#import necessary libraries
import warnings
warnings.filterwarnings(“ignore”)
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
import re
names = [‘class’,’text’]
#load the data set
data = pd.read_csv(“/home/soft50/soft50/Sathish/practice/SMSSpamCollection.csv”,sep=”\t”,names = names)
#make it as a data frame
df = pd.DataFrame(data)
#take text data
text = df[‘text’]
print(“Original text data\n\n”,text)
#change text lower cases and removal of white spaces
lower_text = []
for i in range(0,len(text)):
s = str(text[i])
s1 = s.strip()
lower_text.append(s1.lower())
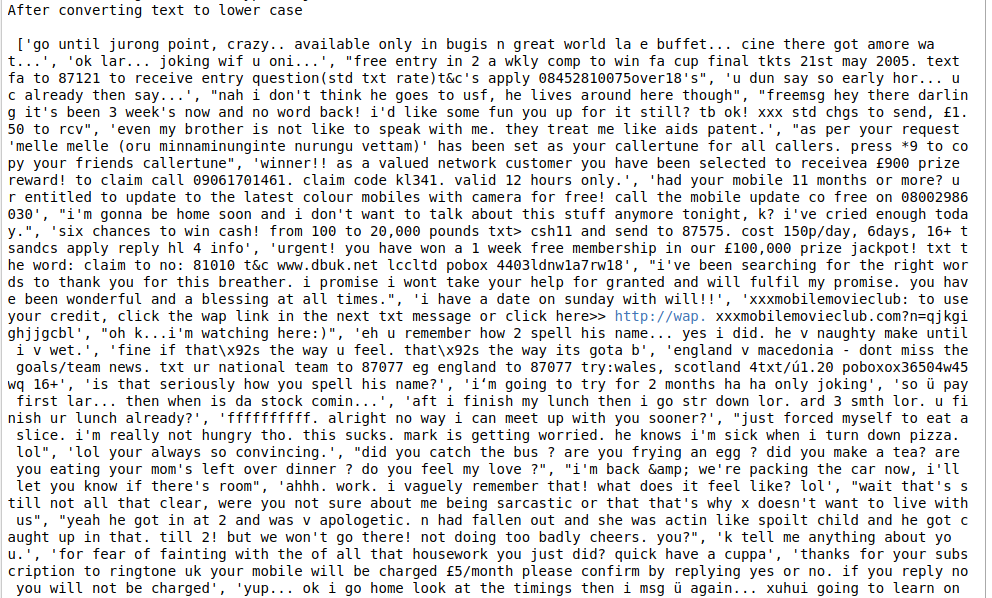
print(“After converting text to lower case\n\n”,lower_text)
#Remove punctuation
punc_text = []
for i in range(0,len(lower_text)):
s2 = (lower_text[i])
s3 = re.sub(r'[^\w\s2]’,”,s2)
punc_text.append(s3)
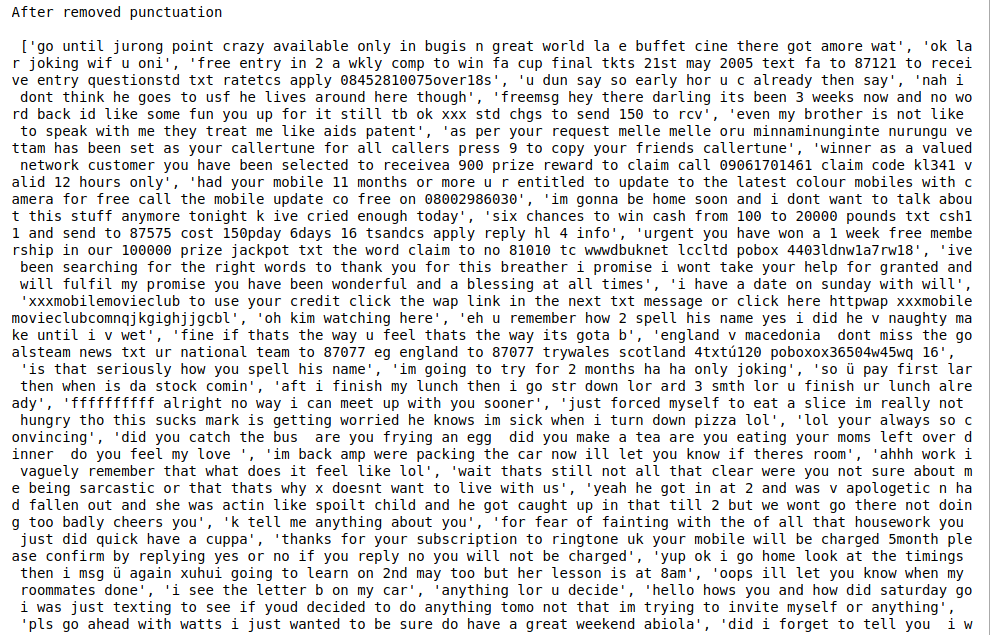
print(“After removed punctuation\n\n”,punc_text)
#Word vectorization
#Initialize the TF-IDF vectorizer
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm=’l2′, encoding=’latin-1′, ngram_range=(1, 2),
stop_words=’english’)
#transform independent variable using TF-IDF vectorizer
X_tfidf = tfidf.fit_transform(punc_text)
print(“After vectorized text data\n\n”,X_tfidf)