#import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
#load the data
data = pd.read_csv(“/home/soft50/soft50/Sathish/practice/Employee.csv”)
#make it data frame
df = pd.DataFrame(data)
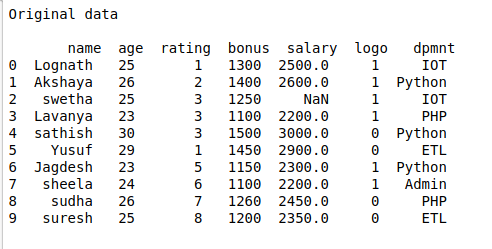
#Original data
print(“Original data\n\n”,df)
print(“\n”)
#Check missing values
print(“Missing values count in each column\n”)
print(df.isnull().sum())
X = df[[‘salary’]]
y = df[‘dpmnt’]
#impute missing values
from sklearn.preprocessing import Imputer
imp = Imputer(strategy=’mean’, axis=0)
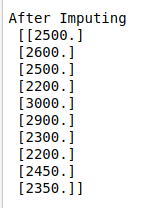
imp_X = imp.fit_transform(X)
print(“\n”)
print(“After Imputing\n”,imp_X)
#Encode the input features
from sklearn.preprocessing import LabelEncoder
enc = LabelEncoder()
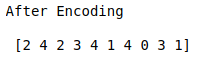
y = enc.fit_transform(y)
print(“\n”)
print(“After Encoding\n\n”,y)