What is Unsupervised ML? In unsupervised learning all the data are unlabelled.
It have input data (x) and no corresponding output (y) variable.
Its goal is to model the underlying structure of the data and to distribute the data.
In order to learn more about the data.
It is grouped into Clustering and Association.
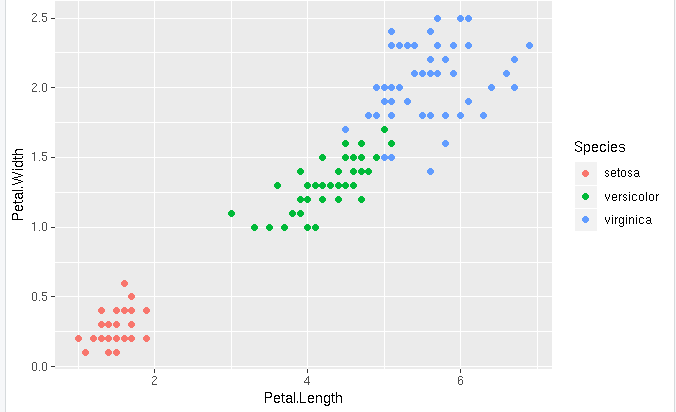
Clustering: To discover groupings in the dataset.
Grouping customers by purchasing behavior.
Centroid based Algorithms : K-means,hierarchical algorithm.
K-means Clustering algorithm: It is a type of Unsupervised learning.
One of the clustering algorithm
It is a centroid based algorithm
To find Patterns in the data.
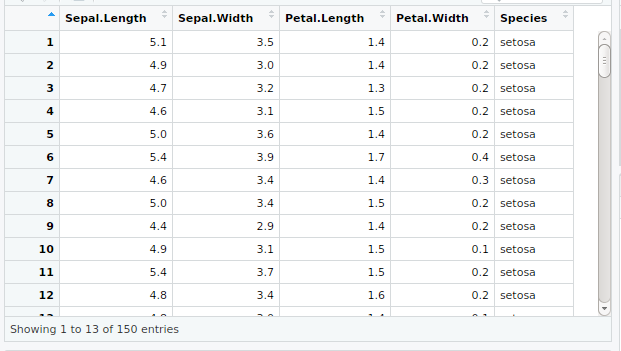
Steps in K-means Clustering: Step 1: Import data.
Step 2: Data Preparation
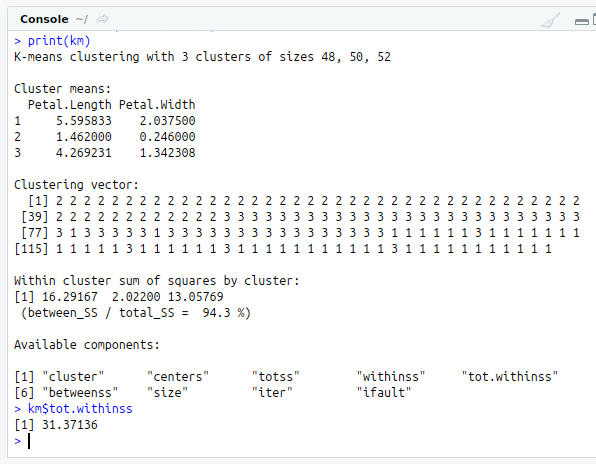
Step 3: Compute kmeans
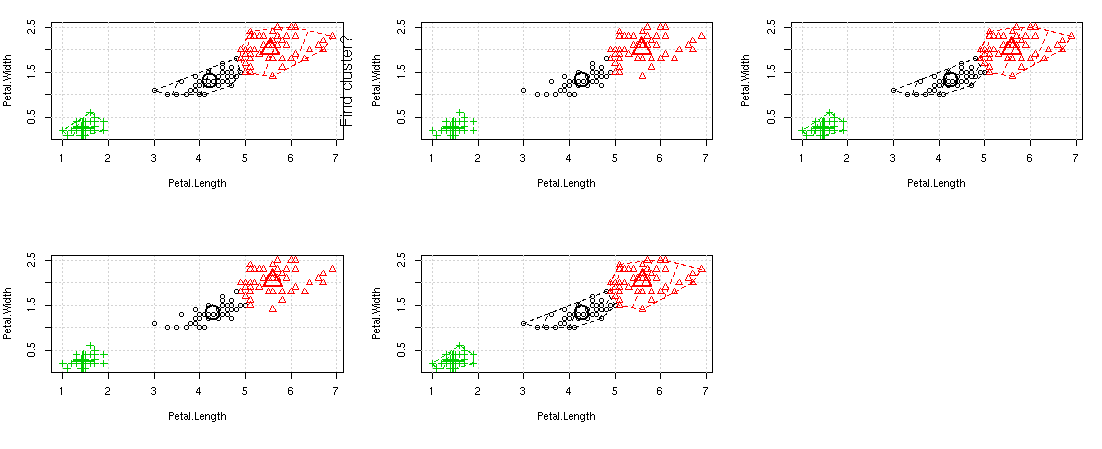
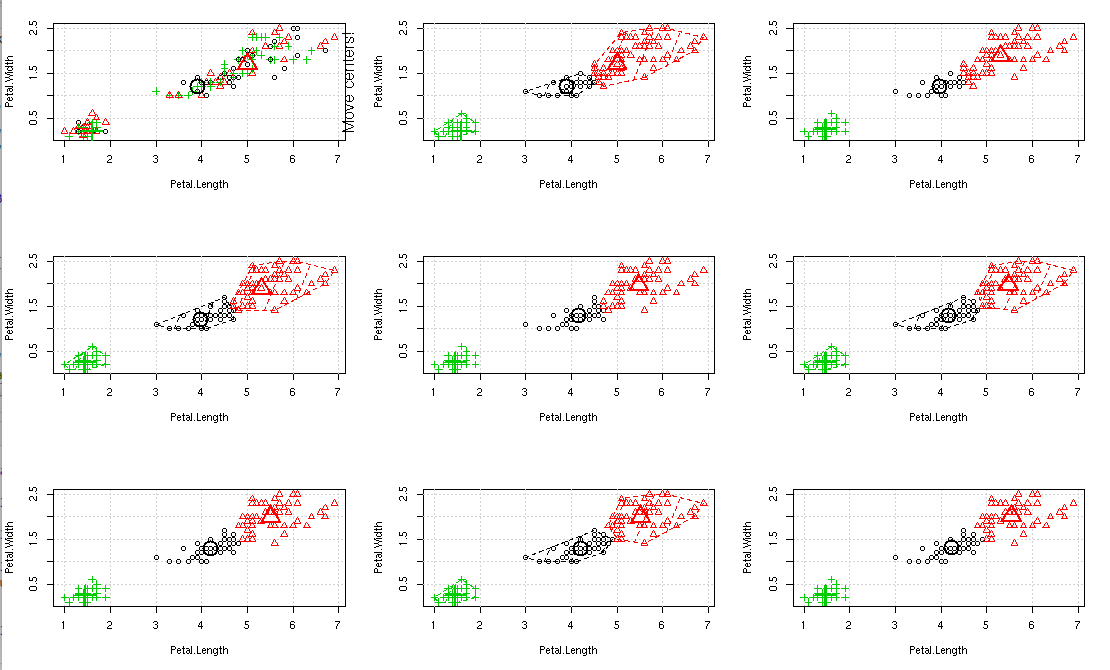
Step 4: Ploting the result.
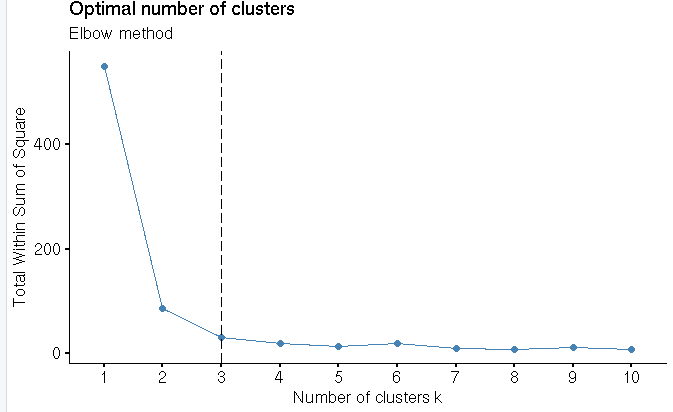
Step 5: Finding the optimal number of clusters.
Package and Functions: R Package :ggplot2--For Visualization
R Package : animation--For animatic visualization
R Package :factoextra--For data manipulation and visualization.
R Package : NbClust--For Visualizing the number of clusters.
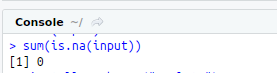
R Function : sum(is.na(data))--to return the number of missing values.
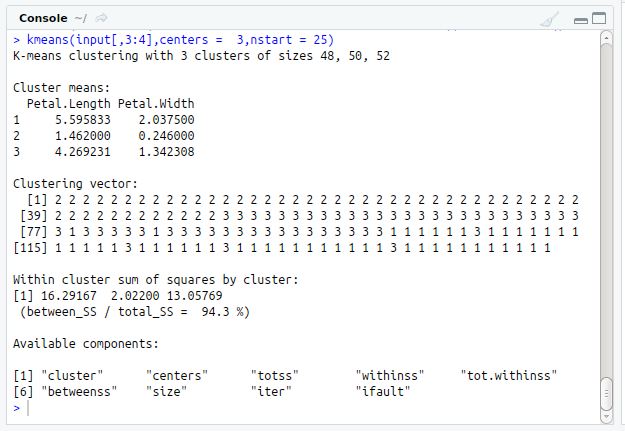
R Function : kmeans(data,centers=,nstart= )-- to compute kmeans.
data--data set to be clustered
centers--No.of Clusters to be formed
nstart --No.of random sets to be chosen initially.
R Function : fviz_nbclust(x,FUNcluster method=c(silhoutte,wss,gap_stat))-from factoextra package used to compute three different methods(silhoutte,elbow,gap statistic) for any partitioning clustering methods(k-means,k-mediods,HCUT)
R Function : par(mfrow=c())--to split the graph screen