#Load the sparklyr library
library(sparklyr)
library(caret)
#Create a spark connection
sc %
ft_r_formula(Gender~.) %>%
ml_logistic_regression()
#Split the data for train and test
partitions=sdf_partition(data_s,training=0.8,test=0.2,seed=111)
train_data=partitions$training
test_data=partitions$test
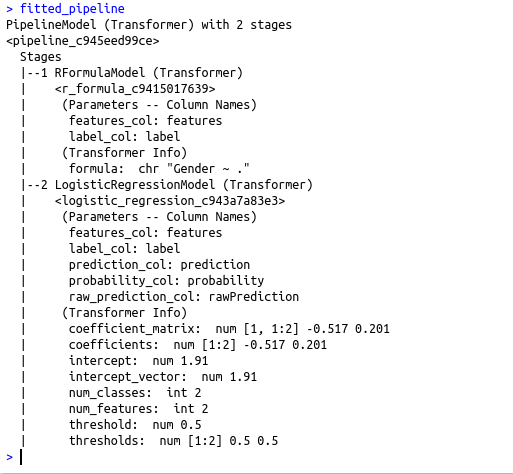
#Fit the pipeline model
fitted_pipeline fitted_pipeline
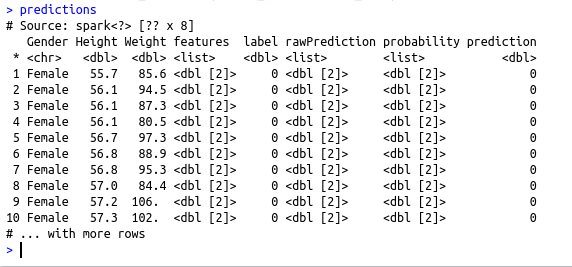
#Predict using the test data
predictions predictions
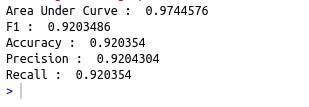
#Evaluate the metrics AUC
cat(“Area Under Curve : “,ml_binary_classification_evaluator(predictions, label_col =”label”,prediction_col = “prediction”))
cat(“\nF1 : “,ml_multiclass_classification_evaluator(predictions, label_col = “label”,prediction_col = “prediction”))
cat(“\nAccuracy : “,ml_multiclass_classification_evaluator(predictions, label_col = “label”,prediction_col = “prediction”,metric_name=”accuracy”))
cat(“\nPrecision : “,ml_multiclass_classification_evaluator(predictions, label_col = “label”,prediction_col = “prediction”,metric_name=”weightedPrecision”))
cat(“\nRecall : “,ml_multiclass_classification_evaluator(predictions, label_col = “label”,prediction_col = “prediction”,metric_name=”weightedRecall”))