#Load the sparklyr library
library(sparklyr)
#Create a spark connection
sc #Copy data to spark environment
data_amz #To tokenize the data(split sentence into words)
tkn=ft_tokenizer(data_amz,input_col=”V1″,output_col=”Tokenized”)
#To remove the stop words
stp_rem=ft_stop_words_remover(tkn,input_col=”Tokenized”,output_col =”Stp_rmvd”)
#To Map a sequence of ter#Load the sparklyr library
library(sparklyr)
#Create a spark connection
sc #Copy data to spark environment
data_amz #To tokenize the data(split sentence into words)
tkn=ft_tokenizer(data_amz,input_col=”V1″,output_col=”Tokenized”)
#To remove the stop wordsms to their term frequencies using the hashing trick
hashed=ft_hashing_tf(stp_rem,input_col = “Stp_rmvd”,output_col = “Hash”)
#To compute the Inverse Document Frequency (IDF)
idf=ft_idf(hashed,input_col=”Hash”,output_col=”IDF”)
#Split the data for train and test
partitions=sdf_partition(idf,training=0.8,test=0.2,seed=111)
train_data=partitions$training
test_data=partitions$test
#Build the naive bayes model
nb_model=ml_naive_bayes(x =train_data,V2~IDF)
#Predict using the test data
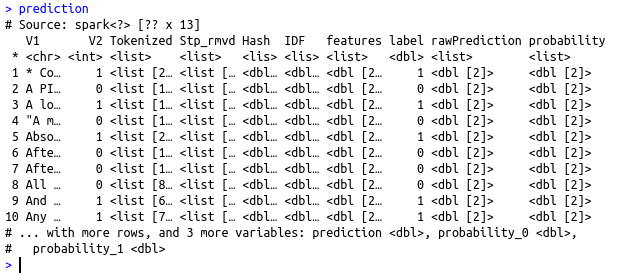
prediction = ml_predict(nb_model, test_data)
prediction
#Evalute the metrics
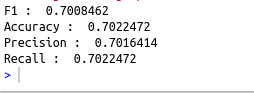
cat(“F1 : “,ml_multiclass_classification_evaluator(prediction, label_col = “label”,
prediction_col = “prediction”))
cat(“\nAccuracy : “,ml_multiclass_classification_evaluator(prediction, label_col = “label”,
prediction_col = “prediction”,metric_name=”accuracy”))
cat(“\nPrecision : “,ml_multiclass_classification_evaluator(prediction, label_col = “label”,
prediction_col = “prediction”,metric_name=”weightedPrecision”))
cat(“\nRecall : “,ml_multiclass_classification_evaluator(prediction, label_col = “label”,
prediction_col = “prediction”,metric_name=”weightedRecall”))