Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To Tokenize a given text and remove punctuation using the regular expression in R
Load the necessary libraries
Load the data set
Transform the data set into a format as required(Skip this step if it is in proper format)
Tokenize the text by splitting the text using the space character
Find where the punctuation are present and replace it with an empty character
library(“readtext”)
data data1=(strsplit(data$text,”\n”))
data2=unlist(data1[[1]])
data3=strsplit(data2,”\t”)
data4=unlist(data3)
i=0
j=0
k=0
text=c()
pol=c()
for (i in (1:length(data4)))
{
if(i%%2!=0)
{
j=j+1
text[j]=data4[i]
}else
{
k=k+1
pol[k]=data4[i]
}
}
df=data.frame(text=text,polarity=pol,stringsAsFactors = FALSE)
#Split the data with the space character to tokenize each word
v1=strsplit(df$text,” “)
#Now add the tokenized data as a new column to the existing data frame
df$tokenized_data df$tokenized_data
#To remove the punctuation
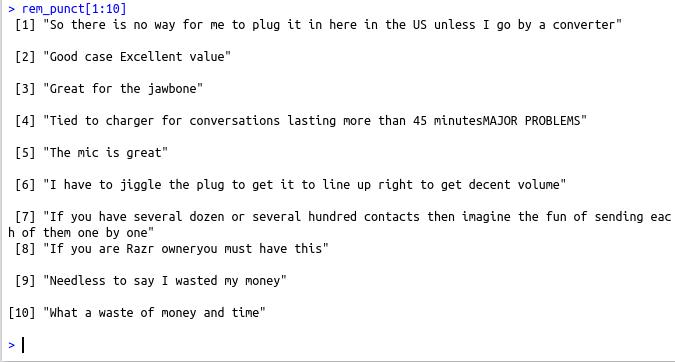
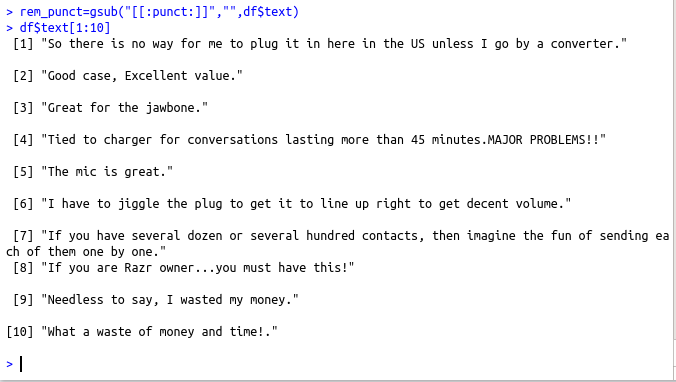
rem_punct=gsub(“[[:punct:]]”,””,df$text)
df$text[1:10]
rem_punct[1:10]