Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To implement linear regression in spark with R using SparklyR package
spark_connect(master = “local”) – To create a spark connection
sdf_copy_to(spark_connection,R object,name) – To copy data to spark environment
sdf_partition(spark_dataframe,partitions with weights,seed) – To partition spark dataframe into multiple groups
ml_linear_regression(train_data,formula) – To build a linear regression model
ml_predict(ml_model,test_data) – To predict the response for the test data
ml_regression_evaluator(predict,label_col,prediction_col,metric_name) – To evaluate the metrics(RMSE(default),MSE,R2,MAE)
#Load the sparklyr library
library(sparklyr)
#Create a spark connection
sc #Copy data to spark environment
data_s=sdf_copy_to(sc,read.csv(“……./servo.csv”),”servo”,overwrite= TRUE)
#Split the data for training and testing
partitions=sdf_partition(data_s,training=0.8,test=0.2,seed=111)
train_data=partitions$training
test_data=partitions$test
#Build the linear regression model
ml_linear_regression(x =train_data,Class~.)
summary(lr_model)
#Predict using the test data
prediction = ml_predict(lr_model, test_data)
#Evaluate the metrics
#Default RMSE(Root Mean Square Error)
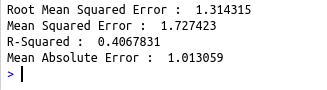
cat(“Root Mean Squared Error : “,ml_regression_evaluator(prediction, label_col = “Class”,prediction_col = “prediction”))
cat(“\nMean Squared Error : “,ml_regression_evaluator(prediction, label_col = “Class”,prediction_col = “prediction”,metric_name = “mse”))
cat(“\nR-Squared : “,ml_regression_evaluator(prediction, label_col = “Class”,prediction_col = “prediction”,metric_name = “r2”))
cat(“\nMean Absolute Error : “,ml_regression_evaluator(prediction, label_col = “Class”,prediction_col = “prediction”,metric_name = “mae”))