Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To implement linear regression using Spark with R
#Set up spark home
Sys.setenv(SPARK_HOME=”…./spark-2.4.0-bin-hadoop2.7″)
.libPaths(c(file.path(Sys.getenv(“SPARK_HOME”), “R”, “lib”), .libPaths()))
#Load the library
library(SparkR)
#Initialize the Spark Context
#To run spark in a local node give master=”local”
sc #Start the SparkSQL Context
sqlContext #Load the data set
data = read.df(“file:///…./servo.csv”,”csv”,header = “true”, inferSchema = “true”, na.strings = “NA”)
#Split the data into train and test set
splt_data=randomSplit(data,c(8,2))
trainingData=splt_data[[1]]
testData=splt_data[[2]]
xtest=select(testData,”Motor”,”Screw”,”Pgain”,”Vgain”)
ytest=select(testData,”Class”)
#Build the model
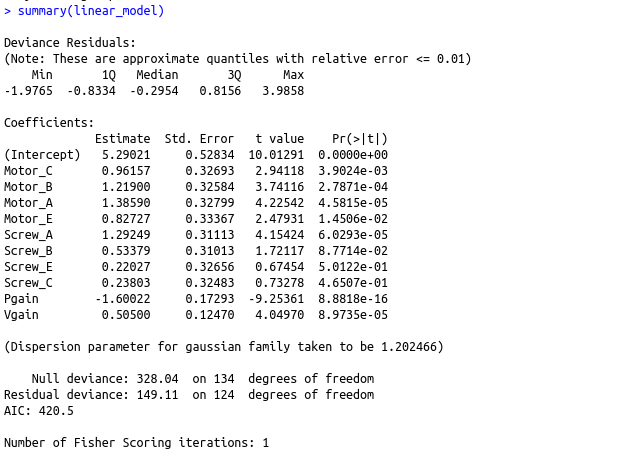
linear_model summary(linear_model)
#Predict using the test data
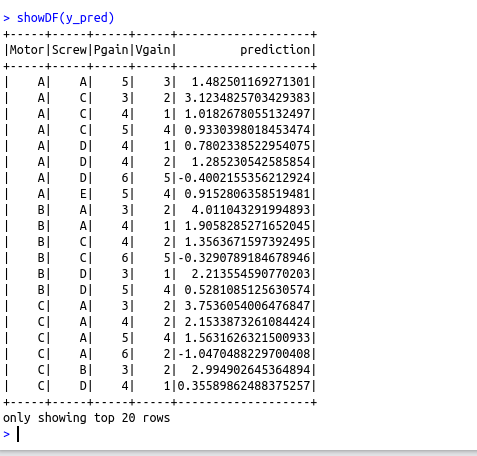
y_pred=predict(linear_model,xtest)
showDF(y_pred)