Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To implement decision tree model for classification using Spark with python
Set up Spark Context and Spark session
Load the Data set
Deal with categorical data and Covert the data to dense vectors(Features and Label)
Transform the dataset to dataframe
Identify categorical features, and index them
Split the data into train and test set
Build and train the decision tree model
Predict using the test set
Evaluate the metrics
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler,IndexToString
from pyspark.sql.functions import col
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.classification import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix,accuracy_score
#Set up SparkContext and SparkSession
spark=SparkSession \
.builder \
.appName(“Python spark regression example”)\
.config(“spark.some.config.option”,”some-value”)\
.getOrCreate()
#Load the data set
df=spark.read.format(‘com.databricks.spark.csv’).options(header=’True’,inferschema=’True’).load(“/home/…./zoo.csv”)
# Automatically identify categorical features, and index them.
def get_dummy(df,categoricalCols,continuousCols,labelCol):
indexers = [ StringIndexer(inputCol=c, outputCol=”{0}_indexed”.format(c))
for c in categoricalCols ]
encoders = [ OneHotEncoder(inputCol=indexer.getOutputCol(),
outputCol=”{0}_encoded”.format(indexer.getOutputCol()))
for indexer in indexers ]
assembler = VectorAssembler(inputCols=[encoder.getOutputCol() for encoder in encoders]
+ continuousCols, outputCol=”features”)
pipeline = Pipeline(stages=indexers + encoders + [assembler])
model=pipeline.fit(df)
data = model.transform(df)
data = data.withColumn(‘label’,col(labelCol))
return data.select(‘features’,’label’)
catcols=[]
catcols =[i for i in df.columns[1:13]]
catcols.append(“15”)
catcols.append(“16”)
catcols.append(“17”)
catcols
num_cols = [“14″]
labelCol = ’18’
data = get_dummy(df,catcols,num_cols,labelCol)
# Index labels, adding metadata to the label column
labelIndexer = StringIndexer(inputCol=’label’,outputCol=’indexedLabel’).fit(data)
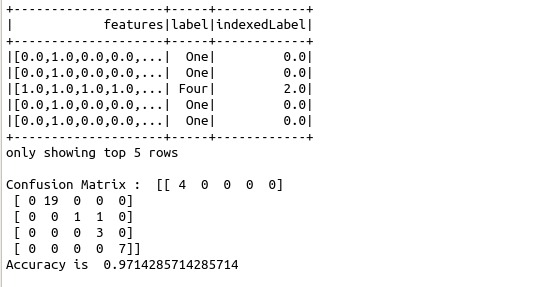
labelIndexer.transform(data).show(5, True)
# Set maxCategories so features with > 8 distinct values are treated as continuous.
featureIndexer =VectorIndexer(inputCol=”features”, \
outputCol=”indexedFeatures”, \
maxCategories=8).fit(data)
# Split the data into training and test sets (20% held out for testing)
(trainingData, testData) = data.randomSplit([0.7, 0.3])
dt = DecisionTreeClassifier(labelCol=”indexedLabel”, featuresCol=”indexedFeatures”)
labelConverter = IndexToString(inputCol=”prediction”, outputCol=”predictedLabel”,
labels=labelIndexer.labels)
# Chain indexers and tree in a Pipeline
pipeline = Pipeline(stages=[labelIndexer, featureIndexer, dt,labelConverter])
# Train model. This also runs the indexers.
model = pipeline.fit(trainingData)
# Make predictions.
predictions = model.transform(testData)
# Evaluate the metrics
y_true = predictions.select(“label”).toPandas()
y_pred = predictions.select(“predictedLabel”).toPandas()
cnf_matrix = confusion_matrix(y_true, y_pred)
print(“Confusion Matrix : “,cnf_matrix)
print(“Accuracy is “,accuracy_score(y_true, y_pred))