Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To resolve missing values of a data frame in spark using python
df.fillna(fillvalue) – To fill NA’s with a given value
df.nadrop() – To drop NA’s
df.na.replace(Value to be replaced,replace with value) – To replace a value with a particular value
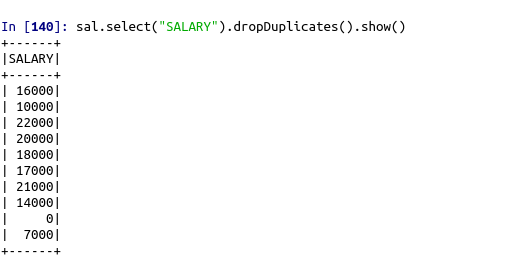
df.dropDuplicates() – To drop the duplicate values
Import necessary libraries
Initialize the Spark session
Create the required data frame
Use the predefined functions to resolve missing values of the data frame
from pyspark.sql import SparkSession
#Set up SparkContext and SparkSession
spark=SparkSession \
.builder \
.appName(“Python spark example”)\
.config(“spark.some.config.option”,”some-value”)\
.getOrCreate()
#Load the file
df1=spark.read.format(‘com.databricks.spark.csv’).options(header=’True’,inferschema=’True’).load(“/home/……/Empm.csv”)
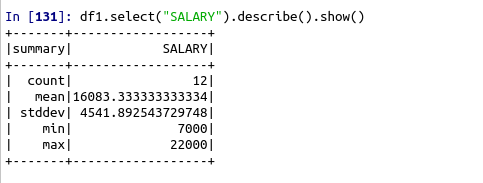
#To get statistical summary of a column
df1.select(“SALARY”).describe().show()
#To fill na of a Column
df1.select(“SALARY”).show()
df1.select(“SALARY”).fillna(16083.33).show()
#To drop the null values
df1.select(“SALARY”).show()
df1.select(“SALARY”).na.drop().show()
#To fill na with 0 and then replace with other value
sal=df1.select(“SALARY”).fillna(0)
sal.show()
sal.na.replace(0,16083.33).show()
#To drop duplicate values
sal.select(“SALARY”).dropDuplicates().show()