Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To know how to interface different data files in R.
Changing current directory :
Reading a csv file :
Syntax :
Variable_name=read.csv(“filename.csv”)
To access the columns :
Ex: data$Name,data$ID,data$Salary
Analyzing the file data :
Adding a new row to the existing file :
Adding a new column to the existing file :
Writing csv file :
Syntax :
write.csv(newdata,”filename.csv”,rownames=FALSE)
#get the current working directory
print(getwd())
#set the current directory
setwd(“/home/soft23/soft23/Aks”)
print(getwd())
data<-read.csv(“Emp.csv”)
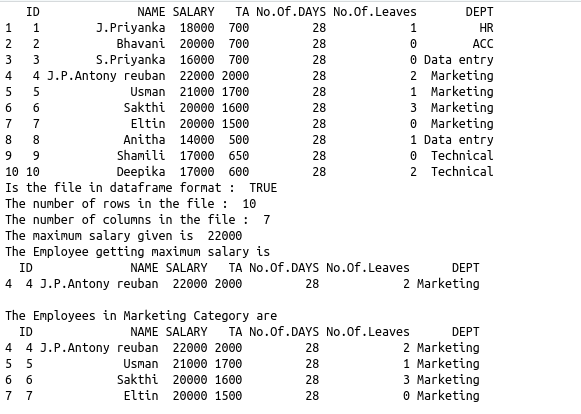
print(data)
cat(“Is the file in dataframe format : “,is.data.frame(data),”\n”)
cat(“The number of rows in the file : “,nrow(data))
cat(“\nThe number of columns in the file : “,ncol(data))
cat(“\nThe maximum salary given is “,max(data$SALARY))
cat(“\nThe Employee getting maximum salary is\n”)
print(subset(data,SALARY==max(SALARY)))
cat(“\nThe Employees in Marketing Category are \n”)
print(subset(data,DEPT==”Marketing”))
nd=data.frame(ID=c(11,12),NAME=c(“Amutha”,”Saranya”),SALARY=c(14000,14000),TA=c(600,600),No.Of.DAYS=c(28,28),No.Of.Leaves=c(1,1),DEPT=c(“Data entry”,”Data entry”))
data=rbind(data,nd)
write.csv(data,”Emp.csv”,row.names=FALSE)
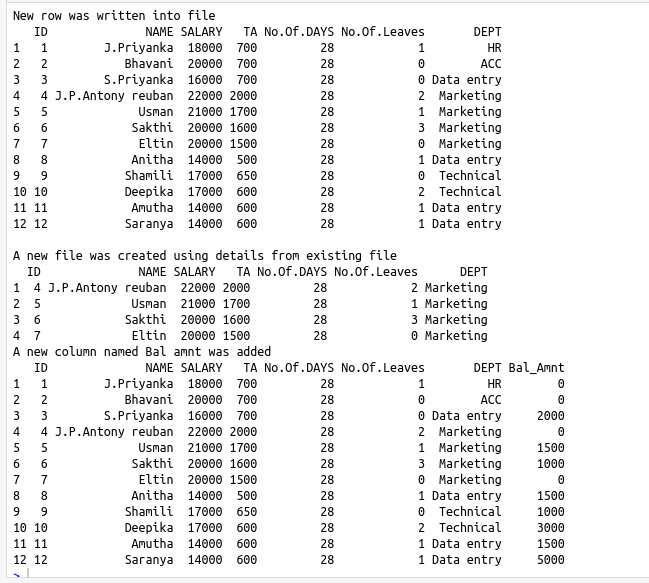
cat(“\nNew row was written into file\n”)
print(read.csv(“Emp.csv”))
newentry=subset(data,DEPT==”Marketing”)
write.csv(newentry,”Mdept.csv”,row.names=FALSE)
cat(“\nA new file was created using details from existing file\n”)
print(read.csv(“Mdept.csv”))
nd1=data.frame(Bal_Amnt = c(0,0,2000,0,1500,1000,0,1500,1000,3000,1500,5000))
data=cbind(data,nd1)
write.csv(data,”Emp.csv”,row.names=FALSE)
cat(“A new column named Bal amnt was added\n”)
print(read.csv(“Emp.csv”))