Load the data set
Find and resolve the Missing values
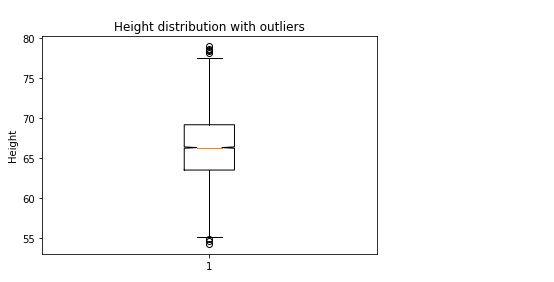
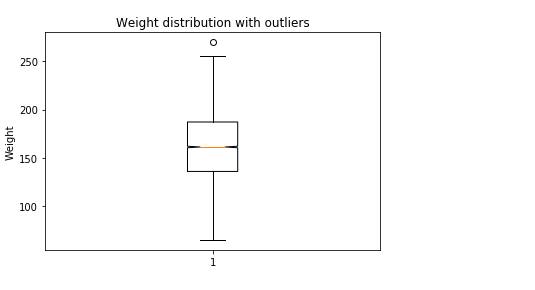
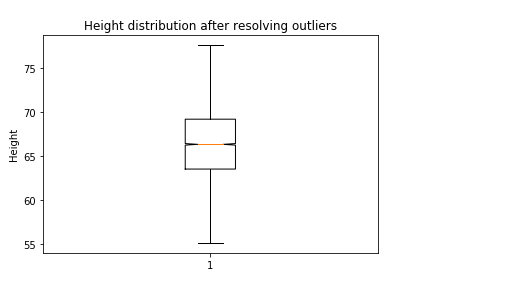
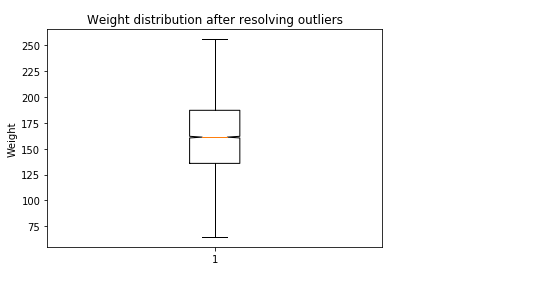
Find and resolve the Outliers
Split the data set for training and testing with ratio 80:20 so that training and testing data has 80% and 20% of the original data set respectively
Build the model
Fit the model using the training data
Test the model using the test data
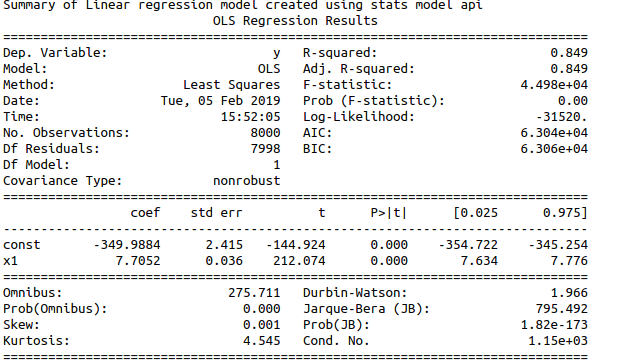
Take the summary and analyse it
Building a simple linear regression model : Simple linear regression model can be created in python in two different methods.They are
Using sklearn library
Using statsmodel api
Using sklearn library : Required libraries : from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
Functions used : To split the data - x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20, random_state=42)
To build the model - reg=LinearRegression()
To train the model - reg.fit(x_train_data,y_train_data)
To test the model - reg.predict(x_test_data)
To find the R -Squared value - reg.score(x_test,y_test)
To find the R-Squared value using metrics library - metrics.r2_score(y_test,y_pred)
Using statsmodel api : Required libraries : import statsmodels.api as sm
Functions used : To Train the model - model = sm.OLS(y_train,x_train)
To fit the model - results = model.fit()
To test the model - results.predict(x_test)
To take the summary -results.summary()