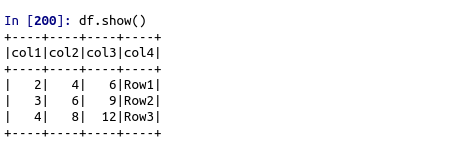Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To Initialize spark session and create data frame in Spark using Python
Import necessary libraries
Initialize the Spark session
Create the required data frame
from pyspark.sql import SparkSession
#Set up SparkContext and SparkSession
spark=SparkSession \
.builder \
.appName(“Python spark example”)\
.config(“spark.some.config.option”,”some-value”)\
.getOrCreate()
#Creating RDD using parallelize function
df = spark.sparkContext.parallelize([(2, 4, 6, ‘Row1’),(3, 6, 9, ‘Row2’),
(4, 8, 12, ‘Row3’)]).toDF([‘col1’, ‘col2’, ‘col3′,’col4′])
df.show()
#Creating RDD uding createDataFrame function
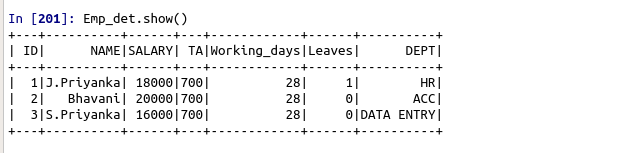
Emp_det = spark.createDataFrame([
(1,’J.Priyanka’,18000,700,28,1,’HR’),
(2,’Bhavani’,20000,700,28,0,’ACC’),
(3,’S.Priyanka’,16000,700,28,0,’DATA ENTRY’)],
[“ID”,”NAME”,”SALARY”,”TA”,”Working_days”,”Leaves”,”DEPT”])
Emp_det.show()
#Using read and load function
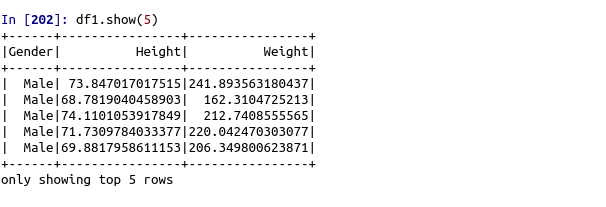
df1=spark.read.format(‘com.databricks.spark.csv’).options(header=’True’,inferschema=’True’).load(“/home/…../weight-height.csv”)
df1.show(5)