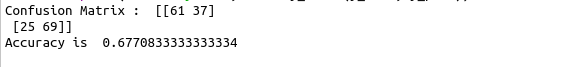Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To perform sentiment analysis using Spark with Python
Set up Spark Context and Spark session
Load the Data set
Create the RDD dataframe
Split the data into train and test set
Tokenize and convert the data into fixed-length feature vector
Down weight columns which appear frequently in a corpus using IDF Estimator
Build and train the model
Predict using the test set
Evaluate the metrics
import pyspark
from pyspark.sql import SQLContext
from pyspark.ml.feature import HashingTF, IDF
from pyspark.ml import Pipeline
from pyspark.ml.feature import Tokenizer
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType
from pyspark.ml.classification import NaiveBayes
from sklearn.metrics import confusion_matrix,accuracy_score
# create spark contexts
sc = pyspark.SparkContext()
sqlContext = SQLContext(sc)
# Load a text file and convert each line to a Row.
data_rdd = sc.textFile(“/home/…../amazon_cells_labelled.txt”)
parts_rdd = data_rdd.map(lambda l: l.split(“\t”))
orgcol_rdd = parts_rdd.filter(lambda l: len(l) == 2)
typed_rdd =orgcol_rdd.map(lambda p: (p[0], float(p[1])))
#Create DataFrame
data_df = sqlContext.createDataFrame(typed_rdd, [“text”,”label”])
(trainingData, testData) = data_df.randomSplit([0.8, 0.2])
#To tokenize the data
tokenizer = Tokenizer(inputCol=”text”, outputCol=”words”)
countTokens = udf(lambda words: len(words), IntegerType())
tokenized = tokenizer.transform(data_df)
hashingTF = HashingTF(inputCol=”words”, outputCol=”rawFeatures”, numFeatures=20)
idf = IDF(inputCol=”rawFeatures”, outputCol=”features”)
#Build and train the model
nb = NaiveBayes()
pipeline = Pipeline(stages=[tokenizer,hashingTF, idf, nb])
model = pipeline.fit(trainingData)
#Test the model using test data
predictions = model.transform(testData)
y_true = predictions.select(“label”).toPandas()
y_pred = predictions.select(“prediction”).toPandas()
type(y_true[“label”][0])
type(y_pred[“prediction”][0])
class_temp = predictions.select(“label”).groupBy(“label”).count().sort(‘count’, ascending=False).toPandas()
class_temp = class_temp[“label”].values.tolist()
cnf_matrix = confusion_matrix(y_true, y_pred,labels=class_temp)
print(“Confusion Matrix : “,cnf_matrix)
print(“Accuracy is “,accuracy_score(y_true, y_pred))