Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To Store data that is extracted from a web page using R
read_html(url) – To scrap the HTML content from a given URL
html_nodes(“.class” or “#id”) – To call nodes based on CSS class or
library(‘selectr’)
library(‘xml2’)
library(‘rvest’)
library(‘stringr’)
library(jsonlite)
Load necessary libraries
Get the URL of the web page
Read the contents of the web page
Get the necessary details from the web page using the predefined functions with the help of the corresponding HTML tags
library(rvest)
library(xml2)
library(stringr)
library(jsonlite)
#Specifying the url for desired website to be scrapped
url1 <-“https://www.indiabookstore.net/isbn/9781606868829”
#Reading the html content from the web page
webpage1 webpage1
#To get the name of the book
title_html title_html
title head(title)
# remove all space and new lines
title=str_replace_all(title, “[\r\t\n]”,””)
#To get the price
price_html price head(price)
#To get the book description
bookdes_html<-html_nodes(webpage1,”span.readable_box_small”)
book_des head(book_des[1])
#To get hte ratings
rating_html rating head(rating)
str_replace_all(rating, “[\r\t\n]”,””)
#To get the number of ratings and reviews
ra_re_html ra_re head(ra_re[1])
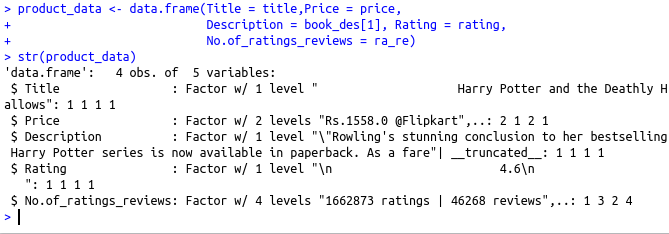
#Combining all the lists to form a data frame
product_data Description = book_des[1], Rating = rating,
No.of_ratings_reviews = ra_re)
#Structure of the data frame
str(product_data)
# convert dataframe into JSON format
json_data # print output
cat(json_data)