Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To implement Random Forest for readingSkills Dataset using R.
x – vector of one or more elements from which to choose
size – a non-negative integer giving the number of items to choose.
data – data frame
ntree – Number of trees to grow
mtry – Number of variables randomly sampled as candidates at each split
model – fitted model
data – New data
#Import data
#install.packages(“party”)
library(“party”)
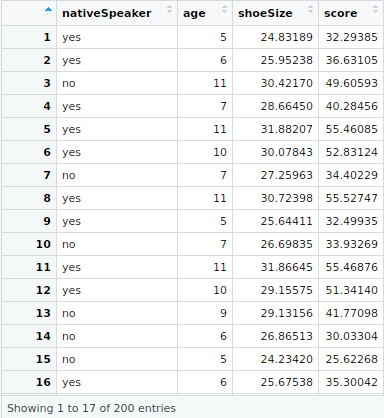
my_input<-readingSkills
View(my_input)
str(my_input)
summary(my_input)
#Check Missing Values
sum(is.na(my_input))
#Splitting into train and test
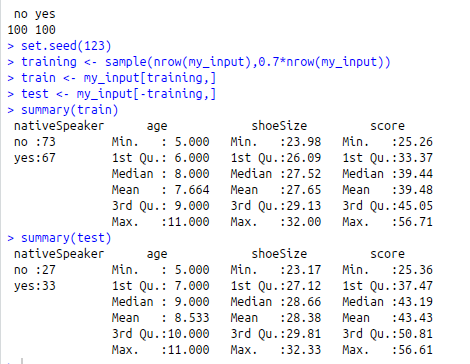
table(my_input$nativeSpeaker)
set.seed(123)
training<-sample(nrow(my_input),0.7*nrow(my_input))
train<-my_input[training,]
test<-my_input[-training,]
summary(train)
summary(test)
#Random Forest Model on train
#install.packages(“randomForest”)
library(“randomForest”)
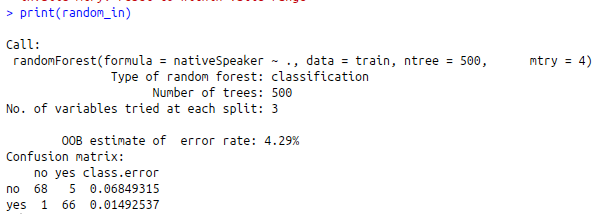
random_in<-randomForest(nativeSpeaker~.,data=train,ntree=500,mtry=4)
print(random_in)
#Preiction on test
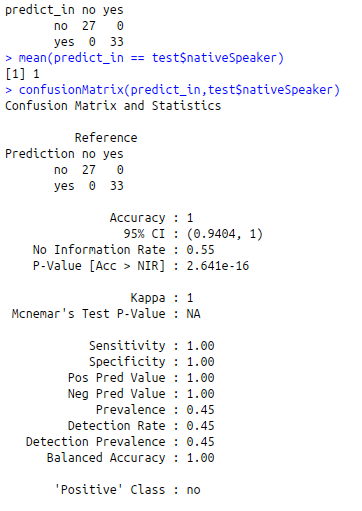
predict_in<-predict(random_in,test)
table(predict_in,test$nativeSpeaker)
mean(predict_in == test$nativeSpeaker)
#Confusion Matrix
confusionMatrix(predict_in,test$nativeSpeaker)
#To check important Variable
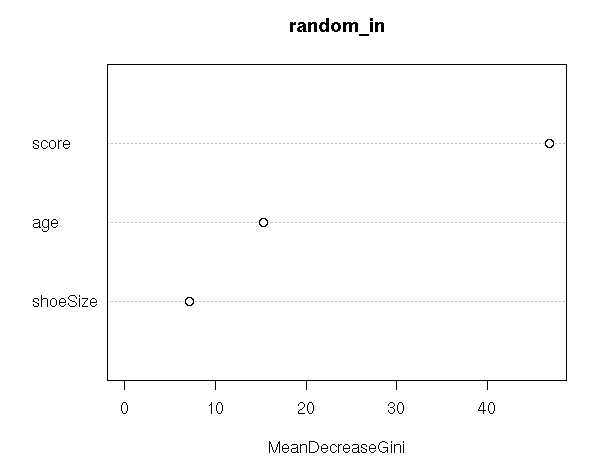
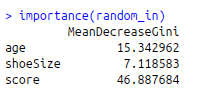
importance(random_in)
varImpPlot(random_in)