Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To save files from spark using R
write.df(df, path =”filepath”) – Save the contents of Spark data frame to a data source(default is parquet)
saveDF(df, path=”filepath”, source =”csv”, mode = “error”) – Save the contents of Spark data frame to a data source(default is parquet)
Source – a name for ecternal data source
Mode – one of ‘append’, ‘overwrite’, ‘error’, ‘errorifexists’, ‘ignore’ save mode (it is ‘error’ by default)
‘append’: Contents of this SparkDataFrame are expected to be appended to existing data.
‘overwrite’: Existing data is expected to be overwritten by the contents of this SparkDataFrame.
‘error’ or ‘errorifexists’: An exception is expected to be thrown.
‘ignore’: The save operation is expected to not save the contents of the SparkDataFrame and to not change the existing data.
library(sparklyr)
#Set up spark home
Sys.setenv(SPARK_HOME=”/…/spark-2.4.0-bin-hadoop2.7″)
.libPaths(c(file.path(Sys.getenv(“SPARK_HOME”), “R”, “lib”), .libPaths()))
#Load the library
library(SparkR)
#Initialize the Spark Context
#To run spark in a local node give master=”local”
sc #Start the SparkSQL Context
sqlContext #Load the data set
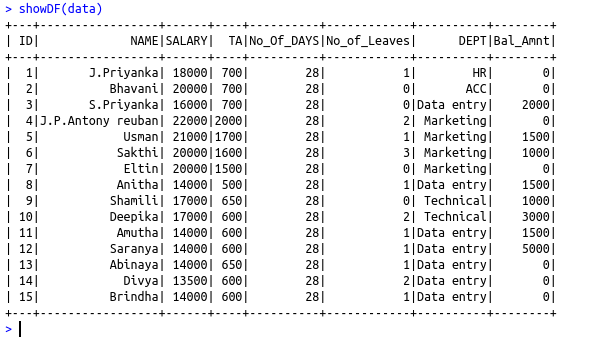
data = read.df(“file:///…/Emp.csv”,”csv”,header = “true”, inferSchema = “true”, na.strings = “NA”)
showDF(data)
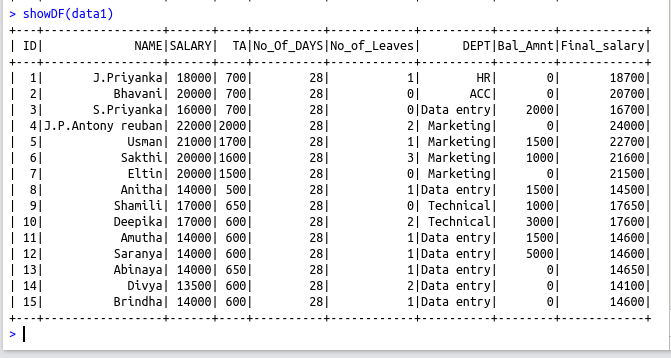
data1 = withColumn(data,”Final_salary”, (data$SALARY+data$TA))
showDF(data1)
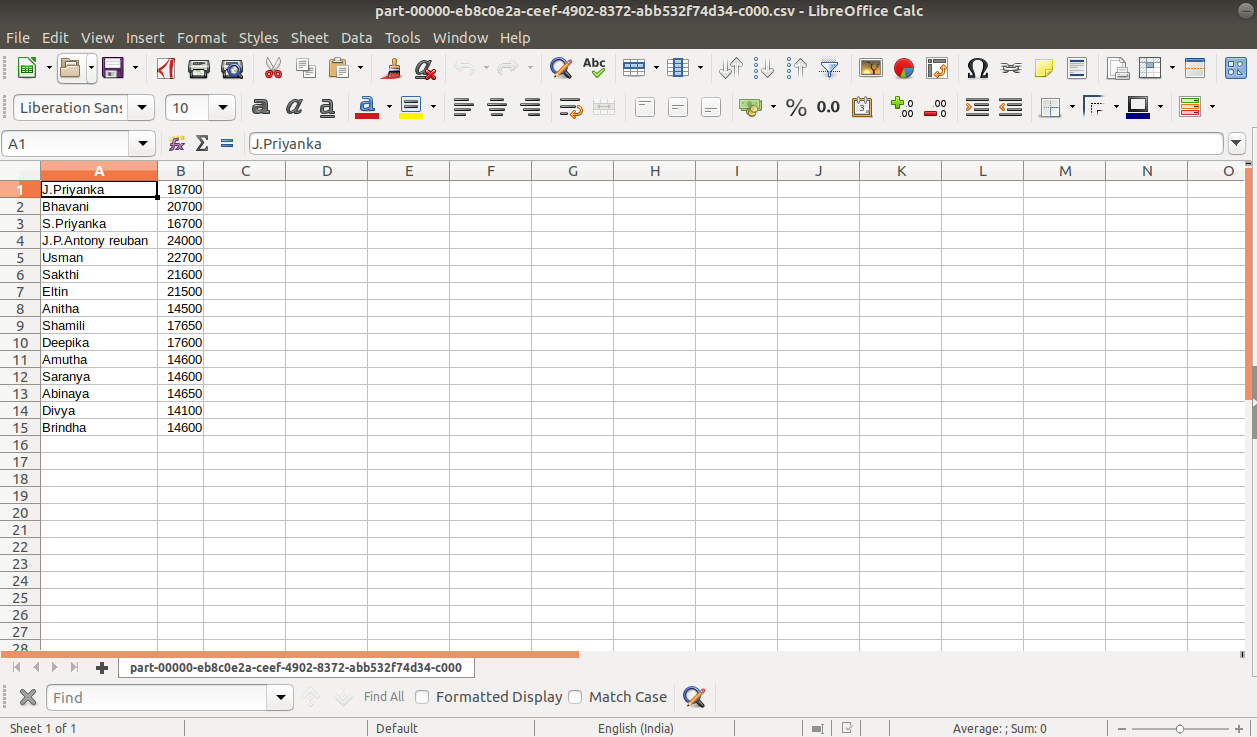
df=select(data1,”NAME”,”Final_salary”)
showDF(df)
#Save the contents of Spark data frame to a data source(default is parquet)
write.df(df, path =”/…./sparkr”)
saveDF(df, path=”/…./sparkr1″, source =”csv”, mode = “error”)