How to Build a Text Classification Model Using GRU for Sentiment Analysis with IMDB Dataset
Share
Condition for Building a Text Classification Model Using GRU for Sentiment Analysis with IMDB Dataset
Description:
The code loads and preprocesses the IMDB dataset by cleaning text, removing
stopwords, and applying TF-IDF vectorization. It then builds an LSTM model
(using a GRU layer) for binary sentiment classification and trains it.
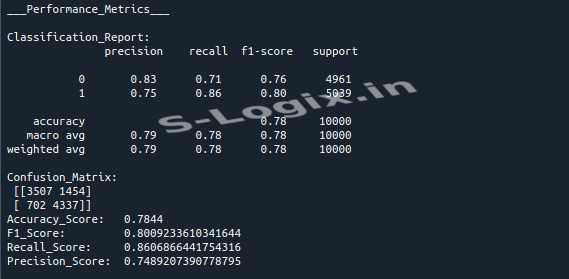
Finally, it evaluates the model's performance using classification metrics
and visualizes the results with a confusion matrix.
Step-by-Step Process
Load Libraries:
Import essential libraries like pandas, sklearn, nltk, and tensorflow for data preprocessing and model building.
Preprocess Text Data:
Clean the text by removing HTML tags, special characters, and stopwords. Tokenize and lemmatize the text.
Encode and Vectorize Data:
Encode sentiment labels and transform the text into numerical features using TF-IDF.
Build and Train Model:
Use GRU as the core layer in an LSTM model, compile it, and train it with the prepared data.
Evaluate and Visualize:
Evaluate the model on the test dataset, generate a classification report, and display a confusion matrix.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, GRU
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Load and preprocess IMDB dataset
df = pd.read_csv("IMDB_Dataset.csv")
# Preprocess text
def preprocess_text(text):
text = re.sub(r'<.*?>', '', text)
text = re.sub(r'[^a-zA-Z\s]', '', text)
tokens = word_tokenize(text.lower())
stop_words = set(stopwords.words('english'))
tokens = [WordNetLemmatizer().lemmatize(word) for word in tokens if word not in stop_words]
return ' '.join(tokens)
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix