How to Build a Text Classification Model Using LSTM for Binary Classification
Share
Condition for Building a Text Classification Model Using LSTM for Binary Classification
Description:
This code demonstrates how to preprocess text data for binary classification
by cleaning and vectorizing it using TF-IDF. It then builds an LSTM model to
classify the text, incorporating dropout layers for regularization. Finally, the
model's performance is evaluated using various metrics like accuracy, F1 score,
and confusion matrix.
Step-by-Step Process
Import the dataset and select the relevant columns for text and labels.
Identify and drop rows with missing values.
Plot the class distribution using a bar plot to check for class imbalance.
Convert text to lowercase, clean HTML tags, URLs, and special characters.
Tokenize the text and remove stopwords, then apply lemmatization to normalize words.
Convert text data into numerical features using TF-IDF vectorization.
Reshape the features to match the input requirements of the LSTM model (3D tensor).
Split the dataset into training and test sets.
Define an LSTM model with dropout layers for regularization and a sigmoid output for binary classification.
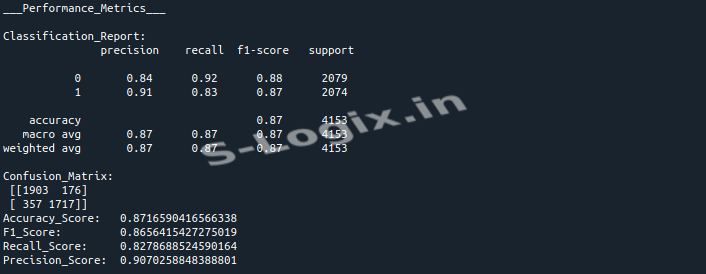
Train the model and evaluate its performance using accuracy, F1 score, recall, precision, and confusion matrix.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense, Dropout, Input, LSTM
from tensorflow.keras.models import Model
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score, f1_score, recall_score, precision_score)
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("/home/soft12/Downloads/sample_dataset/Website/Dataset/fake_train.csv")
df = data.iloc[:, 3:]
# Display initial rows of the dataset
print("Initial data preview:")
print(df.head())
# Check for Nan values
print("Check for Nan values\n")
print(df.isna().sum())
# If Nan values present
df = df.dropna()
# Check for Null Values
print("Check for Null Values\n")
print(df.isnull().sum())
# Plotting the class distribution
plt.figure(figsize=(6, 4))
sns.countplot(x='label', data=df, palette='viridis')
plt.title('Class Distribution')
plt.xlabel('Class')
plt.ylabel('Count')
plt.show()
# Define the preprocessing functions
def preprocess_text(text):
text = text.lower()
text = clean_text(text)
tokens = word_tokenize(text)
stopwords_set = set(stopwords.words('english'))
tokens = [lemmatizer.lemmatize(word) for word in tokens if word not in stopwords_set]
preprocessed_text = ' '.join(tokens)
return preprocessed_text
def clean_text(text):
# Remove HTML tags using regex
text = re.sub(r'<.*?>', '', text)
# Remove URLs
text = re.sub(r'http\S+', '', text)
# Remove non-ASCII characters except periods
text = re.sub(r'[^\x00-\x7F.]', ' ', text)
# Remove special characters except periods
text = re.sub(f'[{re.escape(string.punctuation.replace(".", ""))}]', '', text)
# Remove isolated numbers
text = re.sub(r'\b\d+\b', '', text)
# Replace multiple periods with a single space
text = re.sub(r'\.{2,}', ' ', text)
# Remove extra spaces after periods
text = re.sub(r'(?<=\.)\s+', ' ', text).strip()
return text
# Apply preprocessing to the text column
text_data = df['text'].apply(preprocess_text)
# Build the model
lstm_model = Model(inputs=inputs, outputs=output_layer)
# Compile the model with Adam optimizer and binary crossentropy loss function
lstm_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return lstm_model
model = LSTM_model((X_train.shape[1], X_train.shape[2]))
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix