How to Build and Evaluate a Deep Neural Network for Air Quality Classification Using TensorFlow and Scikit-Learn
Share
Condition for Building and Evaluating a Deep Neural Network Model for Air Quality Classification
Description: Condition for building and evaluating a deep neural network for air quality classification involves preprocessing the dataset, handling missing values, and scaling features. It includes constructing a model with hidden layers, training it using TensorFlow, and assessing performance using classification metrics. The model predicts air quality levels and is evaluated based on accuracy, F1 score, and confusion matrix.
Process
Necessary libraries: Pandas, Numpy, Scikit-Learn, and TensorFlow are imported for data manipulation, model building, and evaluation. Visualization libraries such as Matplotlib and Seaborn are also included for plotting.
Load the dataset: The dataset is loaded into a Pandas DataFrame using pd.read_csv() from the specified file path. This dataset contains pollution-related features and air quality labels.
Handle missing values: The presence of missing values in the dataset is checked using isnull().sum(). This ensures that the dataset is clean and ready for processing.
Correlation matrix: The correlation matrix of the dataset is computed to understand the relationships between features. A heatmap is plotted to visualize these correlations.
Label encoding: The categorical 'Air Quality' column is converted into numeric values using LabelEncoder(). This transformation prepares the target variable for model training.
Independent and dependent variables: Independent variables (X) are selected by dropping the 'Air Quality' column, while the dependent variable (y) is the 'Air Quality' column itself.
Scaling the data: The feature data is scaled using StandardScaler() to ensure that all features are on the same scale, improving the model's performance and convergence.
Train-test split: The dataset is split into training and testing sets using train_test_split(). This division allows for training the model on one subset and evaluating it on another.
Define the Deep Neural Network (DNN): A Deep Neural Network (DNN) model is defined with input, hidden, and output layers using TensorFlow's Keras API. The model uses ReLU activations for hidden layers and softmax for multi-class classification.
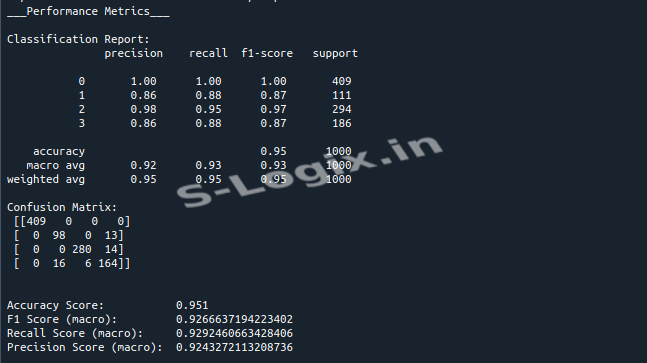
Model training and evaluation: The model is trained using the training data for 50 epochs, and predictions are made on the test set. The performance is evaluated using metrics like accuracy, confusion matrix, and F1 score, followed by visualization of the confusion matrix.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.models import Model
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score, f1_score, recall_score, precision_score)
# Build the model
ann_model = Model(inputs=inputs, outputs=output_layer)
# Compile the model with Adam optimizer and binary crossentropy loss function
ann_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix