How to Build and Evaluate a Multi-Layer Perceptron (MLP) Classifier for Predicting Student Depression
Share
Condition for Building and Evaluating a Multi-Layer Perceptron (MLP) Classifier for Student Depression Prediction
Description:
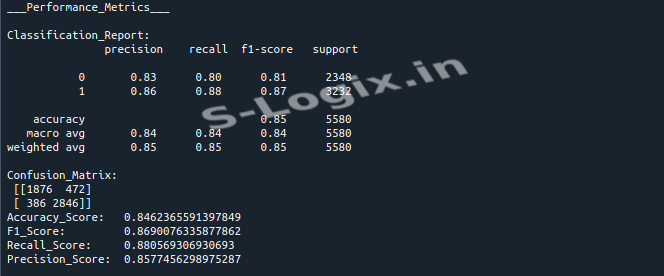
This code preprocesses a student depression dataset by handling missing values, encoding categorical features, and scaling the input data. It then builds and trains a Multi-Layer Perceptron (MLP) classifier to predict student depression based on various features. The model's performance is evaluated using classification metrics like accuracy, precision, recall, F1 score, and confusion matrix.
Step-by-Step Process
Import Libraries: Import necessary libraries like pandas, sklearn, and matplotlib for data processing and model evaluation.
Load and Inspect Dataset: Load the student depression dataset and check for missing or null values.
Preprocess Data: Handle missing values, encode categorical features, and scale the input features.
Build and Train Model: Build an MLP classifier with specified hidden layers and train it on the preprocessed data.
Evaluate Model: Evaluate the model using classification metrics and visualize the results using a confusion matrix.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score,
f1_score, recall_score, precision_score)
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix