How to Build a Predictive Model for Telephone Churn Using MLP Classifier
Share
Condition for Preprocessing and Predicting Telephone Churn Using MLP Classifier
Description: This code preprocesses a telephone churn dataset by encoding categorical variables, handling missing values, and scaling the features. It then trains an MLP Classifier on the data to predict customer churn. Finally, the model's performance is evaluated using confusion matrix, classification report, and accuracy metrics.
Step-by-Step Process
Import Libraries: Import necessary libraries such as pandas, sklearn, matplotlib, seaborn, and MLPClassifier for preprocessing and model building.
Load and Inspect Data: Load the dataset from a CSV file and inspect for missing or null values.
Preprocess Data: Handle missing values, encode categorical variables, and scale features using StandardScaler.
Train Model: Train the MLP Classifier on the preprocessed dataset with training and testing data split.
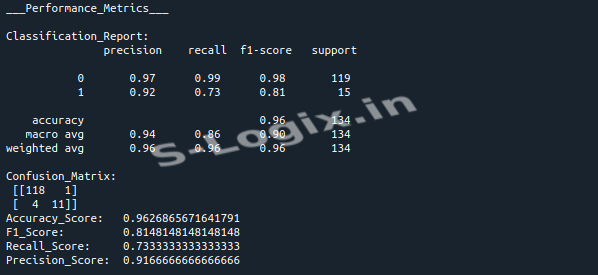
Evaluate and Visualize: Evaluate the model's performance using metrics like classification report, confusion matrix, and accuracy score, and visualize the results using a heatmap.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score, f1_score, recall_score, precision_score)
df = pd.read_csv("/home/soft12/Downloads/sample_dataset/Website/Dataset/churn-bigml-20.csv")
# Check Nan values
print("Check Nan values\n")
print(df.isna().sum())
# Check Data types
print("\n")
print("Check Data types\n")
print(df.dtypes)
# Convert object type columns into numeric
label = LabelEncoder()
for i in df.columns:
if df[i].dtypes == 'object':
df[i] = label.fit_transform(df[i])
elif df[i].dtypes == 'bool':
df[i] = df[i].astype(int)
# Compute the correlation matrix
correlation_matrix = df.corr()
# Display the correlation matrix
print(correlation_matrix)
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix