How to Perform Text Classification Using Word2Vec and LSTM
Share
Condition for Text Classification Using Word2Vec and LSTM
Description: The process involves loading and preprocessing a dataset for text classification. Text data is cleaned, tokenized, and lemmatized before being transformed into Word2Vec embeddings. These embeddings are used to train an LSTM-based model, which is evaluated on its performance using various metrics.
Step-by-Step Process
Import necessary libraries for text preprocessing, machine learning, and deep learning, including pandas, numpy, nltk, gensim, and tensorflow.
Read the dataset using pandas and drop any unnecessary columns, like 'Unnamed: 0', to focus on relevant data.
Inspect the dataset for NaN and null values to ensure clean data before processing. Remove rows with NaN values.
Plot a count of the class labels (e.g., positive or negative) to understand the dataset's class balance.
Clean the text by converting to lowercase, removing HTML tags, URLs, punctuation, and non-ASCII characters. Tokenize the text and lemmatize words.
Use nltk's word_tokenize to split the text into individual tokens for further processing.
Train a Word2Vec model on the tokenized text, which generates word embeddings for each token.
Convert each tokenized text into an embedding vector by averaging the embeddings of its words using the trained Word2Vec model.
Reshape the Word2Vec features into a 3D array suitable for input into the LSTM model (i.e., (samples, time_steps, features)).
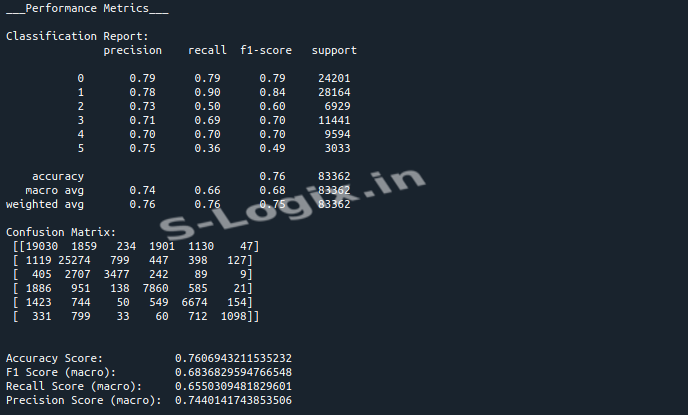
Define the LSTM model with two LSTM layers and a dense output layer. Train the model on the Word2Vec features and evaluate its performance using accuracy, F1-score, and confusion matrix.
Sample Source Code
#Import Necessary Libraries
import pandas as pd
import numpy as np
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense, Dropout, Input, LSTM
from tensorflow.keras.models import Model
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score,
f1_score, recall_score, precision_score)
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
import seaborn as sns
# Load your dataset
data = pd.read_csv("/home/soft12/Downloads/sample_dataset/Website/Dataset/text.csv")
df = data.drop(['Unnamed: 0'], axis=1)
# Display initial rows of the dataset
print("Initial data preview:")
print(df.head())
# Check for Nan values
print("Check for Nan values\n")
print(df.isna().sum())
# Drop rows with NaN values
df = df.dropna()
# Check for Null Values
print("Check for Null Values\n")
print(df.isnull().sum())
# Plotting the class distribution
plt.figure(figsize=(6, 4))
sns.countplot(x='label', data=df, palette='viridis')
plt.title('Class Distribution')
plt.xlabel('Class')
plt.ylabel('Count')
plt.show()
# Define the preprocessing functions
def preprocess_text(text):
text = text.lower()
text = clean_text(text)
tokens = word_tokenize(text)
stopwords_set = set(stopwords.words('english'))
tokens = [lemmatizer.lemmatize(word) for word in tokens if word not in stopwords_set]
preprocessed_text = ' '.join(tokens)
return preprocessed_text
def clean_text(text):
# Remove HTML tags using regex
text = re.sub(r'<.*?>', '', text)
# Remove URLs
text = re.sub(r'http\S+', '', text)
# Remove non-ASCII characters except periods
text = re.sub(r'[^\x00-\x7F.]', ' ', text)
# Remove special characters except periods
text = re.sub(f'[{re.escape(string.punctuation.replace(".", ""))}]', '', text)
# Remove isolated numbers
text = re.sub(r'\b\d+\b', '', text)
# Replace multiple periods with a single space
text = re.sub(r'\.{2,}', ' ', text)
# Remove extra spaces after periods
text = re.sub(r'(?<=\.)\s+', ' ', text).strip()
return text
# Apply preprocessing to the text column
text_data = df['text'].apply(preprocess_text)
# Tokenize the preprocessed text
tokenized_texts = [word_tokenize(text) for text in text_data]
# Generate word embeddings for each sentence
def get_word2vec_vector(tokens):
vector = np.zeros(250) # Vector size of Word2Vec
valid_word_count = 0
for word in tokens:
if word in word2vec_model.wv:
vector += word2vec_model.wv[word]
valid_word_count += 1
if valid_word_count > 0:
vector /= valid_word_count # Average the word vectors
return vector
# Convert the tokenized text to Word2Vec vectors
word2vec_features = np.array([get_word2vec_vector(tokens) for tokens in tokenized_texts])
# Reshape the data for LSTM input (if necessary)
word2vec_features = word2vec_features.reshape(word2vec_features.shape[0], 10, 25)
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix