Life Cycle of Machine Learning and Deep Learning Models
Share
Condition for Life Cycle of Machine Learning and Deep Learning Models
Machine Learning (ML) is a branch of artificial intelligence (AI) that enables systems to learn and improve from experience without being explicitly programmed. It involves developing algorithms that can automatically identify patterns in data and use those patterns to make predictions, decisions, or classifications.
Machine Learning (ML) is often called a lifecycle because it involves a series of interdependent and iterative processes that guide the development, deployment, and maintenance of ML models. These processes work together in a structured way, much like the lifecycle of a product or system, to ensure the continuous improvement and effectiveness of ML solutions.
Machine learning is about development, manipulating data, and modeling. All of these separate parts together form a machine learning project life cycle.
Why Machine Learning is Used in Real-World Applications?
Machine learning (ML) is used in the real world because it addresses problems and optimizes processes that are difficult, time-consuming, or impossible for humans to solve manually. Its primary value lies in its ability to learn from data, identify patterns, and make predictions or decisions, which allows organizations and individuals to improve efficiency, enhance decision-making, and innovate. Here are the main reasons why ML is widely used in the real world:
Automating Repetitive Tasks: ML algorithms can automate tasks previously requiring human intervention, such as data entry, content categorization, or spam filtering. This automation saves time and reduces the risk of human error.
Personalization: ML is extensively used to provide personalized recommendations, such as suggesting movies on Netflix, products on Amazon, or songs on Spotify. It helps businesses create engaging user experiences by tailoring content to individual preferences.
Enhanced Decision-Making: ML models analyze vast amounts of data to provide insights and predictions that support decision-making. For example, in finance, ML helps in risk assessment and investment strategies by analyzing market trends.
Real-Time Problem Solving: In fraud detection applications, ML identifies real-time anomalies, allowing systems to respond immediately. Similarly, ML powers autonomous vehicles by processing sensor data and making split-second decisions to navigate safely.
Scalability: ML enables organizations to handle large-scale operations efficiently. For example, tech companies like Google and Facebook use ML to manage and analyze billions of data points daily, ensuring that their systems can scale with demand.
Unlocking Hidden Insights: ML can uncover patterns and relationships in data that are not immediately visible to humans. This capability is crucial in areas like medical research, where ML aids in discovering new drug interactions or diagnosing diseases from complex datasets.
Predictive Capabilities: One of the greatest strengths of ML is predicting future outcomes based on historical data. For instance, weather forecasting, stock market analysis, and maintenance schedules for machinery are driven by ML models to enhance reliability and preparedness.
Solving Complex Problems: ML is applied in areas like climate modeling, drug discovery, and quantum computing, where traditional computational methods fall short. By leveraging data and adaptive algorithms, ML accelerates progress in these fields.
Cost Efficiency: By automating processes and reducing errors, ML can significantly lower operational costs. For instance, predictive maintenance reduces downtime in manufacturing by identifying potential issues before failures occur.
Advancing Innovation: ML drives technological innovation by enabling the creation of advanced applications like natural language processing (e.g., chatbots, translation tools), generative AI (e.g., creating art and music), and robotics (e.g., autonomous delivery drones).
The Potential Challenges of Machine Learning
Machine learning (ML) faces several challenges affecting its development, deployment, and effectiveness in real-world applications. These challenges stem from the complexities of data, model design, computation, and societal concerns. Below are the main challenges:
Data Challenges: Data Quality and Quantity: High-quality, labeled data is essential for ML models to perform well. Inadequate, noisy, or biased data can lead to inaccurate predictions and unreliable outcomes. Data Accessibility: Many industries face difficulties accessing sufficient data due to privacy concerns, regulations, or logistical constraints. Data Bias: Bias in training datasets can result in models that make discriminatory decisions, which is a critical issue in sensitive domains like healthcare, hiring, or criminal justice.
Model Performance: Overfitting and Underfitting: Overfitting occurs when a model is too complex and captures noise rather than patterns, while underfitting happens when a model is too simplistic to capture the complexity of data. Generalization: Ensuring that ML models perform well on unseen data is a persistent challenge, especially in dynamic environments where data distributions change over time. Interpretability: Complex ML models, such as deep neural networks, often act as “black boxes,” making it difficult for users and stakeholders to understand or trust their predictions.
Computational Requirements: High Costs: Training advanced ML models, particularly deep learning systems, requires substantial computational power, energy, and hardware resources, which may not be accessible to all organizations. Latency: Real-time applications like self-driving cars or fraud detection demand low-latency predictions requiring highly optimized and efficient models.
Deployment and Maintenance: Scalability: Transitioning ML models from prototypes to large-scale production environments can be challenging due to infrastructure and resource requirements differences. Concept Drift: ML models degrade over time as data distributions evolve, necessitating regular monitoring, retraining, and updating. Integration: Embedding ML solutions into existing systems and workflows can require extensive re-engineering.
Ethical and Societal Issues: Privacy Concerns: ML often relies on sensitive data, raising concerns about user privacy and data security. Compliance with regulations like GDPR adds complexity to data handling. Bias and Fairness: Biases in models can perpetuate discrimination, and addressing these biases is both technically and ethically challenging. Job Displacement: The automation enabled by ML can lead to fears about job losses and the societal impact of reduced demand for certain professions.
Adversarial Threats: Adversarial Attacks: ML models can be manipulated by malicious inputs designed to deceive them, leading to incorrect predictions. Security Vulnerabilities: Training processes and deployed models are susceptible to attacks, such as poisoning the training data or extracting sensitive information from models.
Skills Gap: Shortage of Expertise: Developing, deploying, and maintaining ML systems requires specialized skills that are still relatively scarce. This skills gap can hinder adoption and innovation.
Ethical AI Development: Accountability: Determining who is responsible when an ML model makes a harmful or incorrect decision is complex. Transparency: Building trust in AI systems requires clarity about how decisions are made, yet advanced models often lack transparency. Dual-Use Concerns: ML technologies can be misused for harmful purposes, such as creating deepfakes or enabling mass surveillance.
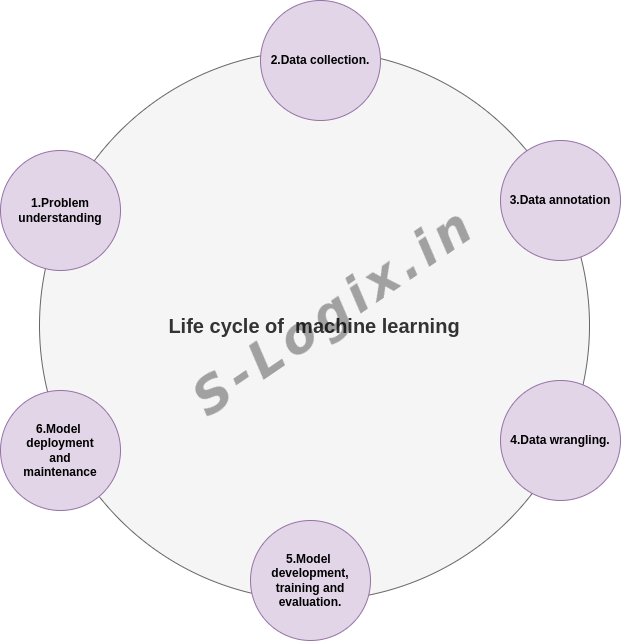
Steps Involved in the Life Cycle of Machine Learning:
The life cycle of a machine learning project can be represented as a multi-component flow, where each consecutive step affects the rest of the flow. Let us look at the steps in a flow on a very high level:
Problem understanding (aka business understanding).
Data collection.
Data annotation.
Data wrangling.
Model development, training, and evaluation.
Model deployment and maintenance in the production environment.
Step:1 Problem understanding
Each project starts with a problem that needs to be solved. Ideally, a clear problem definition should be numerically described. Numbers allow us to know where your starting point is and track the effect of the changes later on.
Discussing this list with the machine learning team, they picked a few tasks that can be solved via supervised
machine learning algorithms if proper data is available.
Finally, the problem understanding is complete: Each team in the company knows what they’re targeting and why. The project can begin.
Step2: Data Collection
Data Collection in Machine Learning (ML) is the process of gathering the relevant data required to train and evaluate machine learning models. Data is the foundation of any ML project, and the quality, quantity, and relevance of the data directly influence the performance of the model. Below is a detailed explanation of data collection in the context of machine learning:
Identify Data Sources: Once the problem is defined, you must identify where to gather the data. Data sources can be categorized as: Internal Sources: These include datasets generated or maintained within an organization. Example: Customer transaction records, user behavior data, logs, and survey responses. External Sources: These include publicly available datasets, APIs, and data provided by third parties.
Example: Datasets from Kaggle, UCI Machine Learning Repository, or data gathered via APIs (e.g., weather data from OpenWeatherMap, stock market data from Yahoo Finance). Synthetic Data: Sometimes real-world data may not be available or sufficient. In such cases, synthetic data can be generated using data augmentation techniques or simulations.
Example: Simulated sensor data for autonomous vehicles or artificially generated images for training computer vision models.
Data Types: Semantic The type of data you need depends on the problem you're solving, and data can be categorized as: Structured Data: Well-organized data, typically in the form of rows and columns, stored in databases or spreadsheets.
Example: Tables of numerical data, such as customer demographics, transaction amounts, or product details. Unstructured Data: Data that doesn't have a predefined structure, requiring special processing to convert it into a usable format.
Example: Text data (e.g., emails, social media posts) or image, audio, and video data. Semi-structured Data: Data that does not conform to a rigid structure like structured data but contains tags or markers that can be parsed.
Example: JSON, XML, or NoSQL databases that store data in a flexible, semi-organized way.
Data Quantity and Quality: Quantity: Generally, more data leads to better model performance because large datasets help the model learn more patterns. However, having a large amount of irrelevant or poor-quality data can lead to overfitting or biased models.
Example: In a fraud detection system, more examples of fraudulent and non-fraudulent transactions help the model distinguish between the two. Quality: High-quality data is critical to building effective ML models. Data should be clean (no missing or erroneous values), representative of the real-world problem, and free of biases.
Example: In medical image analysis, data from diverse patient populations is needed to avoid biased models that perform poorly on underrepresented groups.
Data Labeling: For supervised learning models, data must be labeled. Labeling refers to the process of assigning the correct output (label) to each input data point. Without labels, the data cannot be used for training supervised models. Manual Labeling: Human annotators may manually label the data.
Example: Classifying images of animals as "cat" or "dog." Crowdsourcing: Platforms like Amazon Mechanical Turk allow crowdsourcing of labeling tasks, where workers label data for a fee. Automated Labeling: In some cases, labeling can be partially automated, but manual verification is still needed for quality.
Data Integration: Often, the data used in ML models comes from different sources. Data integration is the process of combining data from these different sources into a unified format to make it usable for training.
Example: Integrating customer demographic data from a CRM system with browsing data collected from a website to predict customer behavior.
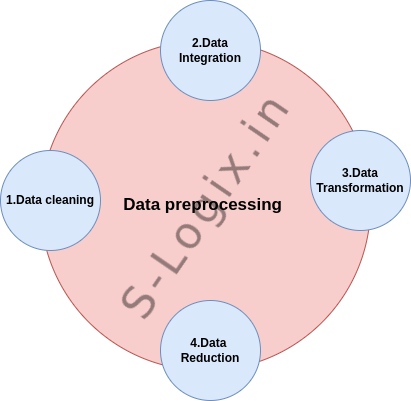
Data Preprocessing: Data preprocessing is an essential step to clean and transform data before it can be used to train a model. The tasks in this step include:
Data Cleaning: Handling missing values, duplicates, or inconsistencies in the data. Missing Values: Here are a few ways to solve this issue: • Ignore those tuples: This method should be considered when the dataset is huge and numerous missing values are present within a tuple. • Fill in the missing values: There are many methods to achieve this, such as filling in the values manually, predicting the missing values using regression method, or numerical methods like attribute mean. Noisy Data: It involves removing a random error or variance in a measured variable. It can be done with the help of the following techniques: Binning: It is the technique that works on sorted data values to smoothen any noise present in it. The data is divided into equal-sized bins, and each bin/bucket is dealt with independently. All data in a segment can be replaced by its mean, median or boundary values. Regression: This data mining technique is generally used for prediction. It helps to smoothen noise by fitting all the data points in a regression function. The linear regression equation is used if there is only one independent attribute; otherwise, polynomial equations are used. Clustering: Creation of groups/clusters from data having similar values. The values that don't lie in the cluster can be treated as noisy data and can be removed. Removing outliers: Clustering techniques group together similar data points. The tuples that lie outside the cluster are outliers/inconsistent data.
Data Integration: Data Integration is one of the data preprocessing steps used to merge the data present in multiple sources into a larger data store like a data warehouse. Data integration is needed, especially when we are aiming to solve a real-world scenario, such as detecting the presence of nodules from CT scan images. The only option is to integrate the images from multiple medical nodes to form a larger database.
Data Transformation: Once data clearing has been done, we need to consolidate the quality data into alternate forms by changing the value, structure, or format of data using the below-mentioned Data Transformation strategies. Generalization: We have converted low-level or granular data to high-level information by using concept hierarchies. We can transform the primitive data in the address, like the city to higher-level information like the country. Normalization: It is the most important data transformation technique and is widely used. The numerical attributes are scaled up or down to fit within a specified range. In this approach, we are constraining our data attribute to a particular container to develop a correlation among different data points. Normalization can be done in multiple ways, which are highlighted here:
Data Reduction: The dataset size in a data warehouse can be too large to handle by data analysis and mining algorithms. One possible solution is to obtain a reduced representation of the dataset that is much smaller in volume but produces the same quality of analytical results.
Handling Ethical and Privacy Issues: Collecting data, especially personal or sensitive data, requires adherence to privacy and ethical standards. For example, in the European Union, the General Data Protection Regulation (GDPR) imposes strict guidelines on collecting, storing, and using personal data. Privacy Concerns: Ensure that personal data is anonymized or pseudonymized to avoid privacy violations. Bias: Ensure the data is representative and does not introduce biases that could affect model fairness. For example, a facial recognition system should be trained on diverse faces to avoid racial biases.
Data Storage: Once data is collected and preprocessed, it must be stored in a way that allows easy access for future use and ensures the integrity of the data. Structured Storage: Relational databases (SQL) are typically used for storing structured data. NoSQL Storage: For semi-structured or unstructured data, NoSQL databases like MongoDB or data lakes can be used. Cloud Storage: For large datasets or projects with scale, cloud-based solutions (AWS, Google Cloud Storage, Azure) are commonly used.
Exploratory Data Analysis (EDA): Machine learning is the initial step in understanding the dataset before applying any machine learning algorithms. EDA helps uncover patterns, identify anomalies, test hypotheses, and check assumptions about the data. This phase is essential because it allows data scientists to gain insights into the data, understand its underlying structure, and prepare it for further processing. Below is an in-depth explanation of EDA in the context of machine learning:
Purpose of Exploratory Data Analysis (EDA): The primary goal of EDA is to: • Understand the dataset: Gain a deeper understanding of the features, their distributions, relationships, and potential outliers. • Identify data quality issues: Detect missing values, duplicates, and outliers that could negatively impact model performance. • Find patterns and relationships: Uncover patterns and correlations between variables that may help in feature engineering or model selection. • Generate hypotheses: Develop hypotheses about the data to guide further analysis, feature selection, or transformation strategies.
Feature Engineering and Transformation: EDA is an excellent time to identify potential new features that could improve model performance. By combining, transforming, or extracting features from existing data, data scientists can create more informative inputs for machine learning algorithms.
Step 4: Data wrangling
Data wrangling, also known as data preprocessing, is the process of cleaning, transforming, and organizing raw data into a format suitable for analysis or modeling. In machine learning (ML), data wrangling is one of the most critical and time-consuming stages of the pipeline. Without proper data wrangling, even the most sophisticated ML algorithms will fail to deliver meaningful insights or accurate predictions.Data wrangling involves tasks like handling missing values, converting data types, normalizing/standardizing data, encoding categorical variables, and detecting outliers. The goal is to ensure that the dataset is well-organized and the features are appropriately prepared for machine learning algorithms.
Data Collection: Before wrangling, data must be collected from various sources like databases, APIs, or raw files (e.g., CSV, JSON, XML). Collected data may be unstructured or semi-structured.
Handling Missing Data: Real-world datasets often have missing values that can impact model performance. Common strategies include: • Dropping rows or columns with excessive missing data. • Imputation using statistical methods like mean, median, or mode. • Interpolation to estimate missing values based on surrounding data points.
Removing or Correcting Errors: Data errors, such as duplicate entries, incorrect data types, or inconsistent formatting, need to be addressed: • Removing duplicate rows. • Correcting data types (e.g., converting strings to numeric or date formats). • Resolving inconsistencies, such as standardizing units or naming conventions.
Data Normalization and Scaling: Machine learning algorithms, especially distance-based ones like k-nearest Neighbors (k-NN) or gradient descent-based models, require features to be on similar scales: • Normalization scales data to a range of [0, 1]. • Standardization scales data to have a mean of 0 and a standard deviation of 1.
Encoding Categorical Variables: Machine learning models typically require numeric input, so categorical variables need to be encoded: • One-Hot Encoding: Creates binary columns for each category. • Label Encoding: Assigns a unique integer to each category. • Ordinal Encoding: Encodes categories with meaningful order into numeric values.
Feature Transformation: Transforming features can help make patterns more visible to machine learning models: • Log Transformations: Used to reduce skewness in distributions. • Polynomial Features: Create interaction terms to capture nonlinear relationships. • Discretization: Group continuous variables into bins.
Feature Selection: Identifying and retaining the most relevant features can improve model efficiency and performance: • Removing redundant features that are highly correlated. • Using techniques like Principal Component Analysis (PCA) for dimensionality reduction.
Outlier Detection and Handling: Outliers can skew model results and degrade performance. Common techniques to handle outliers include: • Removing outliers using statistical methods like Z-scores or the IQR rule. • Transforming or capping extreme values.
Data Integration: Combining data from multiple sources into a single cohesive dataset may involve Merging, joining, or concatenating tables.
Step5: Model Development, Training, and Evaluation
Once data is collected, cleaned, and preprocessed, the next critical steps in the machine learning (ML) pipeline are model development, model training, and model evaluation. These steps are essential for building a predictive model that can make accurate and reliable predictions on unseen data. Let us break down each of these stages.Model development refers to selecting and designing the machine learning model (or algorithm) that will be used to solve the problem at hand. The choice of model depends on the nature of the data, the problem you're trying to solve (classification, regression, clustering, etc.), and the type of insights you want to gain.Model training is the process of feeding the training data to the chosen model so that it can learn the relationships between input features (X) and output labels (y). During training, the model adjusts its internal parameters (e.g., weights in a neural network) to minimize the error or loss between its predictions and the actual target labels.
Overfitting: Overfitting happens when a model learns not only the underlying patterns but also the noise and irrelevant details in the training data. This results in excellent performance on the training dataset but poor generalization to unseen data. Overfitting often arises: • The model is too complex (e.g., deep neural networks or high-degree polynomial models) relative to the amount of training data. • Insufficient regularization techniques (like dropout or L2 regularization) are used. • The dataset contains noise or irrelevant features, and the model memorizes these instead of learning general patterns. Symptoms: High accuracy on training data but low accuracy on validation or test data.
Underfitting: Underfitting occurs when a model is too simple to capture the underlying structure of the data. This leads to poor performance on both the training and validation/test datasets. When it occurs: Underfitting typically arises when: • The model is not complex enough (e.g., using a linear regression model for a highly nonlinear problem). • The training process is insufficient, such as when the model is not trained for enough epochs or lacks relevant features. • Features are not properly preprocessed, or important patterns are missed. Symptoms: Low accuracy on both training and validation/test data, indicating the model hasn’t captured the key patterns in the data.
Training Steps: Dataplit : The dataset is usually divided into training, validation, and test sets. Training Set: Used to train the model. Validation Set: Used to tune hyperparameters and make adjustments to avoid overfitting. Set: Used to evaluate the final model’s performance after training.
Model Evaluation: Once a model has been trained, it needs to be evaluated to ensure it generalizes well to unseen data and meets the objectives of the task. This is done using various performance metrics, which depend on the type of problem (regression, classification, etc.). Evaluation Metrics for Classification: Accuracy: The proportion of correct predictions out of all predictions. Suitable when the classes are balanced. Precision: The proportion of true positive predictions out of all positive predictions. Important when false positives are costly (e.g., spam detection). Recall (Sensitivity): The proportion of true positive predictions out of all actual positive cases. Important when false negatives are costly (e.g., medical diagnosis). F1-Score: The harmonic mean of precision and recall, providing a balance between the two. It's especially useful when classes are imbalanced. ROC-AUC (Receiver Operating Characteristic - Area Under the Curve): A metric for binary classification that plots the true positive rate (recall) against the false positive rate, giving insight into model performance across different thresholds.
Step6: Model Deployment and Maintenance in the Production Environment
Once a machine learning (ML) model has been trained and evaluated, the next crucial phase is deployment—making the model available for real-world use, where it can start making predictions on new, unseen data. However, continuous maintenance is essential to ensure that the model performs well over time, remains accurate, and adapts to data and business needs changes.If the above-prepared model produces an accurate result per our requirement with acceptable speed, then we deploy the model in the real system. However, before deploying the project, we will check whether it is improving its performance using available data or not. The deployment phase is similar to making the final report for a project.
Model Deployment: After training and validating the model, the next step is to deploy it into production so it can be used to make predictions on live data. Deployment involves: Infrastructure setup: Hosting the model on servers, cloud platforms, or edge devices where it can handle requests. Model integration: Integrating the model into applications or workflows where it can interact with end-users or business systems. APIs or interfaces: Creating RESTful APIs or other interfaces to make the model accessible for prediction requests. Example: A fraud detection model in production might be deployed as an API that processes live transaction data and flags suspicious activity.
Model Monitoring: Once deployed, the model's performance must be continuously monitored to ensure it is functioning as expected. Key aspects of monitoring include: Performance Metrics: Track metrics like accuracy, precision, recall, F1 score, and latency to detect degradation in performance. Data Drift: Monitor for changes in the input data distribution, which can lead to performance issues if the live data differs significantly from the training data (e.g., concept drift or covariate shift). Error Analysis: Identify patterns in errors or misclassifications to understand where the model is struggling. Operational Metrics: Measure latency, throughput, and system uptime to ensure the deployment infrastructure is reliable. Example: If a recommendation model starts suggesting irrelevant items, it could indicate data drift or changes in user preferences.
Retraining and Updating the Model: Over time, models can become outdated as data distributions or user requirements evolve. To maintain performance, periodic retraining is necessary: Data Collection: Gather new data from production systems, including user feedback and outcomes, to create updated datasets. Incremental Learning: Update the model incrementally using new data without retraining from scratch. Model Versioning: Maintain multiple versions of the model, ensuring smooth transitions during updates and the ability to roll back if needed. Example: A sentiment analysis model for social media might require retraining as language trends and slang evolve over time.
Feedback Loops: Integrating feedback loops into production systems allows the model to learn from its predictions: Active Learning: Select uncertain or incorrect predictions for labeling and use this labeled data to improve the model. User Feedback: Collect feedback from users on the model’s predictions and incorporate it into the training data. Example: A spam filter can learn from user actions, such as marking emails as "Not Spam," to refine its predictions.
Continuous Improvement: Model maintenance is an ongoing process, requiring a strategy for continuous improvement: AB Testing: Deploy multiple versions of a model to compare their performance in live environments. Experimentation: Test new features, architectures, or algorithms to determine if they improve performance. Automation: Use tools like MLOps platforms to automate data collection, retraining, and deployment pipelines. Example: Model maintenance and production in machine learning are critical to ensuring that models continue to deliver accurate and reliable results over time. This involves deploying the model, monitoring its performance, retraining when necessary, addressing biases, and ensuring scalability and reliability.
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix