Description: TF-IDF stands for Term Frequency-Inverse Document Frequency. It is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. TF-IDF is widely used in text mining and information retrieval to identify important words in a document. TF (Term Frequency): Measures how frequently a word appears in a document. IDF (Inverse Document Frequency): Measures how important a word is within the entire corpus. Words that appear in many documents have a lower weight.
Step-by-Step Process
Import Required Libraries: We need Tf-idf Vectorizer from sklearn.
Create the Text Data: We'll use a list of text documents that we want to transform using TF-IDF.
Initialize the TF-IDF Vectorizer: We initialize the TfidfVectorizer, which will convert our text data into a TF-IDF matrix.
Fit and Transform the Text Data: Now we apply the fit_transform method on our text data to convert it into a TF-IDF matrix.
Sample Code
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# Example text data
text_data = [
"I love programming",
"Programming is fun",
"I love fun",
"I love Python programming"
]
# Initialize TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
# Fit and transform the data
X_tfidf = tfidf_vectorizer.fit_transform(text_data)
# Convert the result to an array and display
print(X_tfidf.toarray())
# View the feature names (vocabulary)
print(tfidf_vectorizer.get_feature_names_out())
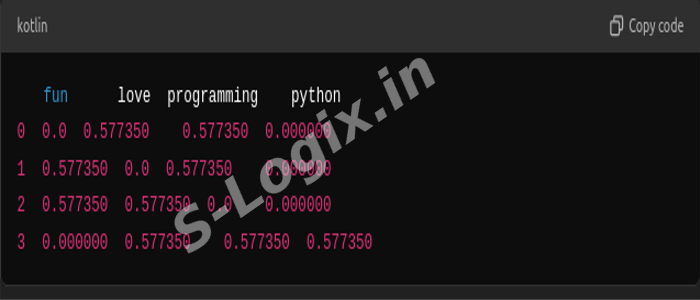
# Convert to a DataFrame
df_tfidf = pd.DataFrame(X_tfidf.toarray(), columns=tfidf_vectorizer.get_feature_names_out())
print(df_tfidf)
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix