How to Perform Word and Sentence Tokenization Using NLTK in Python?
Share
Condition for Performing Word and Sentence Tokenization Using NLTK in Python
Description: Sentence tokenization (sent_tokenize) is the process of splitting a text into individual sentences. It uses punctuation marks like periods, exclamation points, and question marks to identify sentence boundaries and returns a list of sentences. This helps in structuring text for further processing in NLP tasks.
Step-by-Step Process
Import the Necessary Modules: You will need to import the required functions from the nltk.tokenize module.
Sentence Tokenization: Sentence tokenization is the process of splitting a text into sentences. To tokenize a text into sentences, use nltk.sent_tokenize():
Explanation of Tokenization Functions: sent_tokenize(text): Splits the text into a list of sentences. It handles punctuation and other factors, ensuring that text is properly split into sentences.
Sample Code
import nltk
nltk.download('punkt') # Download necessary resources for tokenization
from nltk.tokenize import sent_tokenize, word_tokenize
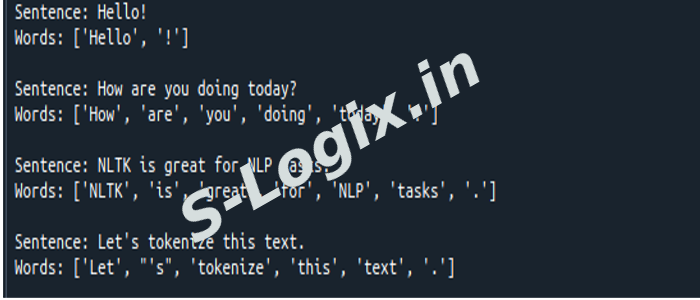
text = "Hello! How are you doing today? NLTK is great for NLP tasks. Let's tokenize this text."
# Sentence Tokenization
sentences = sent_tokenize(text)
# Word Tokenization for each sentence
for sentence in sentences:
words = word_tokenize(sentence)
print(f"Sentence: {sentence}")
print(f"Words: {words}")
print()
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix