How to Implement Word2Vec using Continuous Bag of Words(CBW)?
Share
Condition for Implementing Word2Vec using Continuous Bag of Words(CBW)
Description: Word2Vec is a neural network-based model used to learn distributed word representations (embeddings) from large text corpora. It works by training on context and target word pairs to capture semantic relationships between words. The two main architectures of Word2Vec are Continuous Bag of Words (CBOW), which predicts a target word based on surrounding context, and Skip-gram, which predicts context words from a target word. Word2Vec transforms words into dense, continuous vectors, enabling machines to better understand linguistic meaning.
Step-by-Step Process
Training the Word2Vec Model: The Word2Vec model is trained with parameters like vector_size=100 (which defines the size of word vectors), window=5 (the size of the context window), min_count=1 (ignores words with fewer than one occurrence), workers=4(number of threads to use), and epochs=10 (number of training iterations).
Average Word2Vec Calculation: Given two words (word1 and word2), this function checks if both words exist in the Word2Vec model’s vocabulary. If both words are in the vocabulary, their respective Word2Vec vectors are retrieved. These vectors are then averaged (by taking the mean of the two vectors)to get a single average vector. If either of the words is not found in the vocabulary, a zero vector of the same size as the Word2Vec vectors is returned.
Calculating Average Word Vectors for Consecutive Word Pairs: This function processes a sentence to compute the average vectors for consecutive pairs of words. For each pair of consecutive words in the sentence, it calls the average_word2vec function to compute the average vector between them. The average vector is stored in a dictionary with the word pair as the key.
Example Execution: The example sentence ["word2vec", "models", "convert", "words"] is used to compute the average Word2Vec vectors for consecutive word pairs (e.g., between "word2vec" and "models", "models" and "convert", etc.). The computed average vectors are printed for each consecutive word pair.
Sample Code
from gensim.models import Word2Vec
# Example sentences for training the Word2Vec model
sentences = [
["this", "is", "a", "simple", "example"],
["word2vec", "models", "convert", "words", "to", "vectors"],
["average", "word2vec", "represents", "sentences"],
["word2vec", "is", "a", "popular", "embedding", "model"]
]
# Step 1: Train the Word2Vec model using CBOW (sg=0 for CBOW, sg=1 for Skip-gram)
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4, epochs=10)
# Step 2: Use the trained model to find word vectors
word = "word2vec"
vector = model.wv[word]
# Output the vector for a specific word
print(f"Vector for '{word}':\n{vector}")
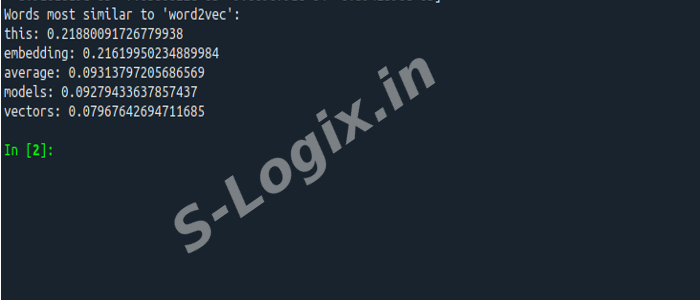
# Step 3: Finding similar words using the trained model
similar_words = model.wv.most_similar(word, topn=5)
print(f"Words most similar to '{word}':")
for similar_word, similarity_score in similar_words:
print(f"{similar_word}: {similarity_score}")
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix




.jpg "Continuous Bag of Words(CBW)")