How to Apply Fault Tolerant Without Replication and Resubmission of Task in Cloud Computing?
Share
Condition for Fault Tolerant Workflow Scheduling Based on Replication and Resubmission of Tasks in Cloud Computing
Description: Fault tolerance without replication and resubmission refers to the ability of a system to continue operating despite the occurrence of failures, without resorting to the duplication of data or services across multiple resources. In this approach, the system employs various techniques and mechanisms to detect, isolate, and recover from failures, ensuring continuous operation and data integrity. Fault-tolerant systems continuously monitor the health and status of system components to proactively identify potential issues and prevent failures before they occur. Monitoring tools and techniques provide administrators with real-time visibility into system performance and reliability.
Sample Code
package ftwswithoutreplication;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.cloudbus.cloudsim.Cloudlet;
import org.cloudbus.cloudsim.Log;
import org.cloudbus.cloudsim.Vm;
import org.workflowsim.CondorVM;
import org.workflowsim.FileItem;
import org.workflowsim.Task;
import org.workflowsim.WorkflowSimTags;
import org.workflowsim.planning.BasePlanningAlgorithm;
import org.workflowsim.scheduling.BaseSchedulingAlgorithm;
import org.workflowsim.scheduling.MaxMinSchedulingAlgorithm;
import org.workflowsim.utils.Parameters;
/**
*
* @author soft29
*/
public class FTWSWitoutReplicationAlgorithm extends BasePlanningAlgorithm {
/**
* ECTMap, OmegaECT - to store expected computation time of each task
*/
Map> ECTMap;
Map> OmegaECT;
/**
* Task List Initialize
*/
List TaskList = new ArrayList();
// to map parent task's id with list of child
Map> mapParentChild = new HashMap<>();
// to map child task's id with list of parent
Map> mapChildParent = new HashMap<>();
// makespan of workflow
double workflowMakespan;
// copy of workflow
List omegaListOfTask;
// makespan of copy of workflow multiplied by replcation factor
double omegaTaskMakespan;
// independent task list
List independentTasks;
//map heuristicMetric with task in a workflow
Map workflowHeuristicMetric;
// to set instruction time ratio to a task
Map instructionTimeRatio;
private Map> schedules;
private Map earliestFinishTimes;
private Map> computationCosts;
private Map> transferCosts;
private double averageBandwidth;
private Map rank;
// for Linear Congurent Method
public FTWSWitoutReplicationAlgorithm() {
super();
ECTMap = new HashMap();
OmegaECT = new HashMap();
independentTasks = new ArrayList();
workflowHeuristicMetric = new HashMap();
instructionTimeRatio = new HashMap();
earliestFinishTimes = new HashMap<>();
schedules = new HashMap<>();
computationCosts = new HashMap<>();
transferCosts = new HashMap<>();
rank = new HashMap<>();
}
@Override
public void run() throws Exception {
ECTMap.putAll(ectCalculate(getTaskList(), 1));
workflowMakespan = maxExecutionTime(ECTMap, true);
// Log.printLine("Makespan of Workflow :" + workflowMakespan);
linearCongurentMethod();
thresholdCalc();
entryNode();
int resubNum = WorkflowParameters.resubmission;
omegaListOfTask = getTaskList();
OmegaECT.putAll(ectCalculate(omegaListOfTask, resubNum));
omegaTaskMakespan = maxExecutionTime(OmegaECT, false);
independentTask();
heuristicMetric(ECTMap, OmegaECT);
instructionTime();
averageBandwidth = calculateAverageBandwidth();
for (Object vmObject : getVmList()) {
CondorVM vm = (CondorVM) vmObject;
schedules.put(vm, new ArrayList<>());
}
calculateComputationCosts();
calculateTransferCosts();
calculateRanks();
allocateTasks();
// algorithm();
}
// Calculate Expected Computational Time for each task
protected Map> ectCalculate(List tasklist, int resubFact) {
Map> ExpectComputTime = new HashMap();
List workflowList = tasklist;
if (!workflowList.isEmpty()) {
List condorVmList = getVmList();
for (Task task : workflowList) {
Map taskVmExecutionTime = new HashMap();
for (Vm vm : condorVmList) {
double exeTime = 0;
exeTime = ((double) (task.getCloudletTotalLength() * resubFact) / (double)(vm.getMips() * vm.getNumberOfPes())) + (double) (task.getCloudletFileSize() / vm.getBw());
taskVmExecutionTime.put(vm, exeTime);
}
ExpectComputTime.put(task, taskVmExecutionTime);
}
}
return ExpectComputTime;
}
protected double maxExecutionTime(Map> taskVmECT, boolean setdeadline) {
Map> ExpectedComputatonTime = taskVmECT;
double makespan = Double.MIN_VALUE;
// Log.printLine("Task Id Deadline");
for (Map.Entry taskExecTime : ExpectedComputatonTime.entrySet()) {
Task task = (Task) taskExecTime.getKey();
Map vmtimeMap = (Map) taskExecTime.getValue();
double maxECT = Double.MIN_VALUE;
for (Map.Entry executionTime : vmtimeMap.entrySet()) {
CondorVM vm = (CondorVM) executionTime.getKey();
double taskExectime = (double) executionTime.getValue();
if (maxECT < taskExectime) {
maxECT = taskExectime;
if (makespan < maxECT) {
makespan = maxECT;
}
}
}
if (setdeadline == true) {
task.setDeadline(maxECT);
}
// Log.printLine(" " + task.getCloudletId() + " " + maxExecutionTime);
}
// Log.printLine("Makespan of Workflow : " + makespan);
return makespan;
}
protected void thresholdCalc() {
List listoftask = getTaskList();
int numoftask = listoftask.size();
// Log.printLine("Task Id Threshold:");
for (Task task : listoftask) {
double threshold = ((double) task.getChildList().size() / (double) numoftask);
task.setCloudletThreshold(threshold);
// Log.printLine(" " + task.getCloudletId() + " " + threshold);
}
}
protected void heuristicMetric(Map> wfECT, Map Map> omegaECT) {
Map workflowMaxECT = new HashMap();
Map omegaMaxECT = new HashMap();
// assign maximum expected computation time to the task in workflow
for (Map.Entry wfect : wfECT.entrySet()) {
Task task = (Task) wfect.getKey();
Map vmtime = (Map) wfect.getValue();
double makespanoftask = Double.MIN_VALUE;
for (Map.Entry ectimeofwf : vmtime.entrySet()) {
Vm vm = (Vm) ectimeofwf.getKey();
double time = (double) ectimeofwf.getValue();
if (makespanoftask < time) {
makespanoftask = time;
}
}
workflowMaxECT.put(task, makespanoftask);
}
// assign maximum expected computation time to a task in copy of workflow(omega)
for (Map.Entry omegaect : omegaECT.entrySet()) {
Task task = (Task) omegaect.getKey();
Map vmtime = (Map) omegaect.getValue();
double makespanoftask = Double.MIN_VALUE;
for (Map.Entry ectimeofomega : vmtime.entrySet()) {
Vm vm = (Vm) ectimeofomega.getKey();
double time = (double) ectimeofomega.getValue();
if (makespanoftask < time) {
makespanoftask = time;
}
}
omegaMaxECT.put(task, makespanoftask);
}
for (Map.Entry wfmaxect : workflowMaxECT.entrySet()) {
Task task = (Task) wfmaxect.getKey();
double ectime = (double) wfmaxect.getValue();
double ectimeOmega = (double) omegaMaxECT.get(task);
double delta = (double) (ectimeOmega - ectime);
double RI = (double) (delta / omegaTaskMakespan);
double heuristicMetrics = RI * (double) WorkflowParameters.replication;
workflowHeuristicMetric.put(task, heuristicMetrics);
task.setHeuristic(heuristicMetrics);
// Log.printLine("Task ID : " + task.getCloudletId() + " Heuristic Metric values :" + heuristicMetrics);
}
}
/*
Find entry node
*/
private void entryNode() {
ParentTask();
int x = Integer.MAX_VALUE;
Task entryTask = null;
for (Map.Entry mapEntry : mapChildParent.entrySet()) {
Task task = (Task) mapEntry.getKey();
List listofparent = (List) mapEntry.getValue();
if (listofparent.isEmpty() && x > task.getCloudletId()) {
x = task.getCloudletId();
entryTask = task;
}
}
// Log.printLine("Entry Task Id :" + entryTask.getCloudletId());
entryTask.setEntryTask(true);
}
/*
/*
Segregate parents and Children tasks
*/
private void ParentTask() {
TaskList = getTaskList();
for (Task t1 : TaskList) {
List childList = new ArrayList();
List parentList = new ArrayList();
childList.addAll(t1.getChildList());
parentList.addAll(t1.getParentList());
mapParentChild.put(t1, childList);
mapChildParent.put(t1, parentList);
}
}
protected void independentTask() {
for (Map.Entry m1 : mapChildParent.entrySet()) {
Task task = (Task) m1.getKey();
List task4 = (List) m1.getValue();
if (task4.isEmpty()) {
independentTasks.add(task);
// Log.printLine(" Independent Tasks Id are = " + task.getCloudletId());
}
}
}
protected void instructionTime() {
for (Task task : getTaskList()) {
double itr = ((double) task.getCloudletLength() / task.getDeadline());
// Log.printLine(" Task length :" + task.getCloudletLength() + " Deadline :" + task.getDeadline());
instructionTimeRatio.put(task, itr);
// Log.printLine("Task Id :" + task.getCloudletId() + " Instruction Time Ratio :" + itr);
}
}
private void calculateComputationCosts() {
for (Task task : getTaskList()) {
Map costsVm = new HashMap<>();
for (Object vmObject : getVmList()) {
CondorVM vm = (CondorVM) vmObject;
if (vm.getNumberOfPes() < task.getNumberOfPes()) {
costsVm.put(vm, Double.MAX_VALUE);
} else {
costsVm.put(vm,
task.getCloudletTotalLength() / vm.getMips());
}
}
computationCosts.put(task, costsVm);
}
}
private void calculateTransferCosts() {
// Initializing the matrix
for (Task task1 : getTaskList()) {
Map taskTransferCosts = new HashMap<>();
for (Task task2 : getTaskList()) {
taskTransferCosts.put(task2, 0.0);
}
transferCosts.put(task1, taskTransferCosts);
}
// Calculating the actual values
for (Task parent : getTaskList()) {
for (Task child : parent.getChildList()) {
transferCosts.get(parent).put(child,
calculateTransferCost(parent, child));
}
}
}
private double calculateTransferCost(Task parent, Task child) {
List parentFiles = parent.getFileList();
List childFiles = child.getFileList();
double acc = 0.0;
for (FileItem parentFile : parentFiles) {
if (parentFile.getType() != Parameters.FileType.OUTPUT) {
continue;
}
for (FileItem childFile : childFiles) {
if (childFile.getType() == Parameters.FileType.INPUT
&& childFile.getName().equals(parentFile.getName())) {
acc += childFile.getSize();
break;
}
}
}
//file Size is in Bytes, acc in MB
acc = acc / 1000000;
// acc in MB, averageBandwidth in Mb/s
return acc * 8 / averageBandwidth;
}
private double calculateAverageBandwidth() {
double avg = 0.0;
for (Object vmObject : getVmList()) {
CondorVM vm = (CondorVM) vmObject;
avg += vm.getBw();
}
return avg / getVmList().size();
}
protected void linearCongurentMethod() {
List serviceslist = DatacenterServices.getDatacenterServices();
List listOfTasks = getTaskList();
int c = 2; // initial seed value
int a = 1; // multiplicative value
int b = 2; // additive value
int M = serviceslist.size(); // number of services
int c1 = 1;
int a1 = 1;
int b1 = 3;
int[] x = new int[listOfTasks.size()];
int[] y = new int[listOfTasks.size()];
for (int i = 0; i < listOfTasks.size(); i++) {
List s = new ArrayList<>();
x[i] = (a * c + b) % M;
y[i] = (a1 * c1 + b1) % M;
s.add(serviceslist.get(x[i]));
s.add(serviceslist.get(y[i]));
// Log.printLine(" Task Id : "+listOfTasks.get(i).getCloudletId());
listOfTasks.get(i).setServices(s);
// Log.printLine(" X[" + i + "] =" + x[i] + " " + " Y[" + i + "] =" + y[i]);
c = x[i];
c1 = y[i];
}
}
protected void taskServices() {
List listoftask = getTaskList();
Log.printLine();
Log.printLine("Random Generation algorithm with uniform distribution");
Log.printLine();
Log.printLine("Task ID " + " Set of services");
for (Task task : listoftask) {
Log.printLine(" " + task.getCloudletId() + " " + task.getServices().get(0) + ", " + task.getServices().get(1));
}
}
private class Event {
public double start;
public double finish;
public Event(double start, double finish) {
this.start = start;
this.finish = finish;
}
}
private double findFinishTime(Task task, CondorVM vm, double readyTime,
boolean occupySlot) {
List sched = schedules.get(vm);
double computationCost = computationCosts.get(task).get(vm);
double start, finish;
int pos;
if (sched.isEmpty()) {
if (occupySlot) {
sched.add(new Event(readyTime, readyTime + computationCost));
}
return readyTime + computationCost;
}
if (sched.size() == 1) {
if (readyTime >= sched.get(0).finish) {
pos = 1;
start = readyTime;
} else if (readyTime + computationCost <= sched.get(0).start) {
pos = 0;
start = readyTime;
} else {
pos = 1;
start = sched.get(0).finish;
}
if (occupySlot) {
sched.add(pos, new Event(start, start + computationCost));
}
return start + computationCost;
}
// Trivial case: Start after the latest task scheduled
start = Math.max(readyTime, sched.get(sched.size() - 1).finish);
finish = start + computationCost;
int i = sched.size() - 1;
int j = sched.size() - 2;
pos = i + 1;
while (j >= 0) {
Event current = sched.get(i);
Event previous = sched.get(j);
if (readyTime > previous.finish) {
if (readyTime + computationCost <= current.start) {
start = readyTime;
finish = readyTime + computationCost;
}
break;
}
if (previous.finish + computationCost <= current.start) {
start = previous.finish;
finish = previous.finish + computationCost;
pos = i;
}
i--;
j--;
}
if (readyTime + computationCost <= sched.get(0).start) {
pos = 0;
start = readyTime;
if (occupySlot) {
sched.add(pos, new Event(start, start + computationCost));
}
return start + computationCost;
}
if (occupySlot) {
sched.add(pos, new Event(start, finish));
}
return finish;
}
private class TaskRank implements Comparable {
public Task task;
public Double rank;
public TaskRank(Task task, Double rank) {
this.task = task;
this.rank = rank;
}
@Override
public int compareTo(TaskRank o) {
return o.rank.compareTo(rank);
}
}
/**
* Invokes calculateRank for each task to be scheduled
*/
private void calculateRanks() {
for (Task task : getTaskList()) {
calculateRank(task);
}
}
private double calculateRank(Task task) {
if (rank.containsKey(task)) {
return rank.get(task);
}
double averageComputationCost = 0.0;
for (Double cost : computationCosts.get(task).values()) {
averageComputationCost += cost;
}
averageComputationCost /= computationCosts.get(task).size();
double max = 0.0;
for (Task child : task.getChildList()) {
double childCost = transferCosts.get(task).get(child)
+ calculateRank(child);
max = Math.max(max, childCost);
}
rank.put(task, averageComputationCost + max);
return rank.get(task);
}
private void allocateTasks() {
List taskRank = new ArrayList<>();
for (Task task : rank.keySet()) {
taskRank.add(new TaskRank(task, rank.get(task)));
}
// Sorting in non-ascending order of rank
Collections.sort(taskRank);
for (TaskRank rank : taskRank) {
allocateTask(rank.task);
}
}
private void allocateTask(Task task) {
CondorVM chosenVM = null;
double earliestFinishTime = Double.MAX_VALUE;
double bestReadyTime = 0.0;
double finishTime;
for (Object vmObject : getVmList()) {
CondorVM vm = (CondorVM) vmObject;
double minReadyTime = 0.0;
for (Task parent : task.getParentList()) {
double readyTime = earliestFinishTimes.get(parent);
if (parent.getVmId() != vm.getId()) {
readyTime += transferCosts.get(parent).get(task);
}
minReadyTime = Math.max(minReadyTime, readyTime);
}
finishTime = findFinishTime(task, vm, minReadyTime, false);
if (finishTime < earliestFinishTime) {
bestReadyTime = minReadyTime;
earliestFinishTime = finishTime;
chosenVM = vm;
}
}
findFinishTime(task, chosenVM, bestReadyTime, true);
earliestFinishTimes.put(task, earliestFinishTime);
task.setVmId(chosenVM.getId());
}
}
Step 1
To create fault tolerant without scheduling model like cloud environment setup, preprocessor step and the simulation operations.
Step 2
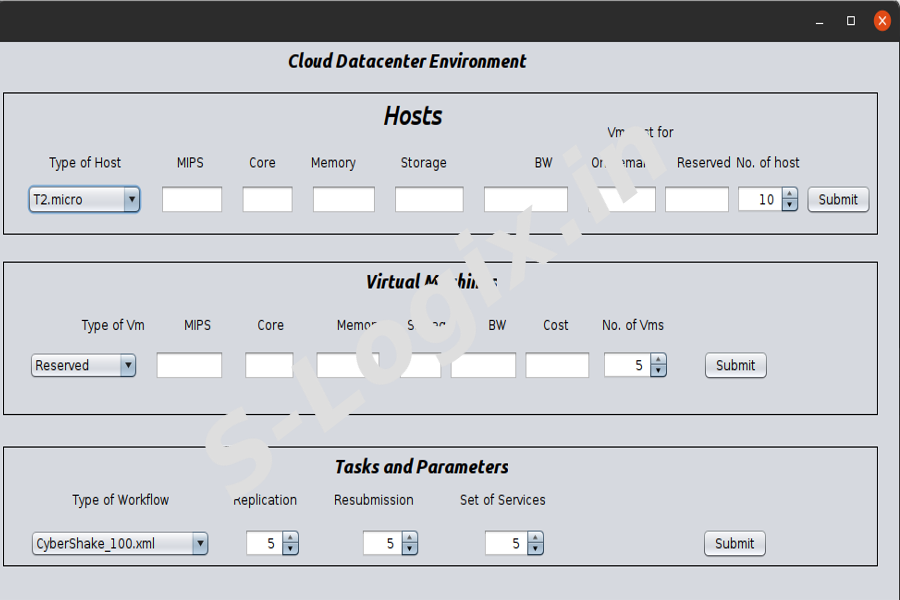
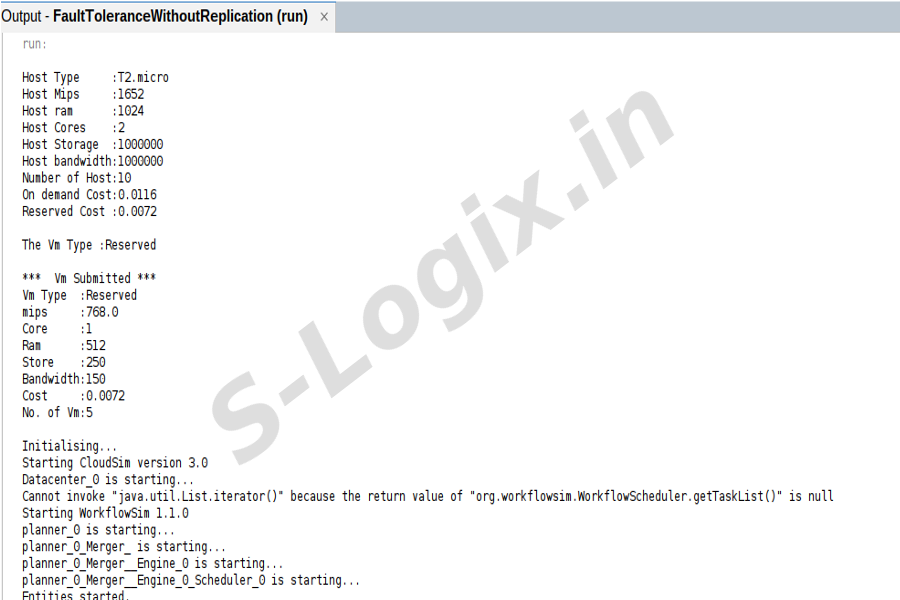
To create a cloud datacenter environment like host, virtual machines, Task and parameters.
Step 3
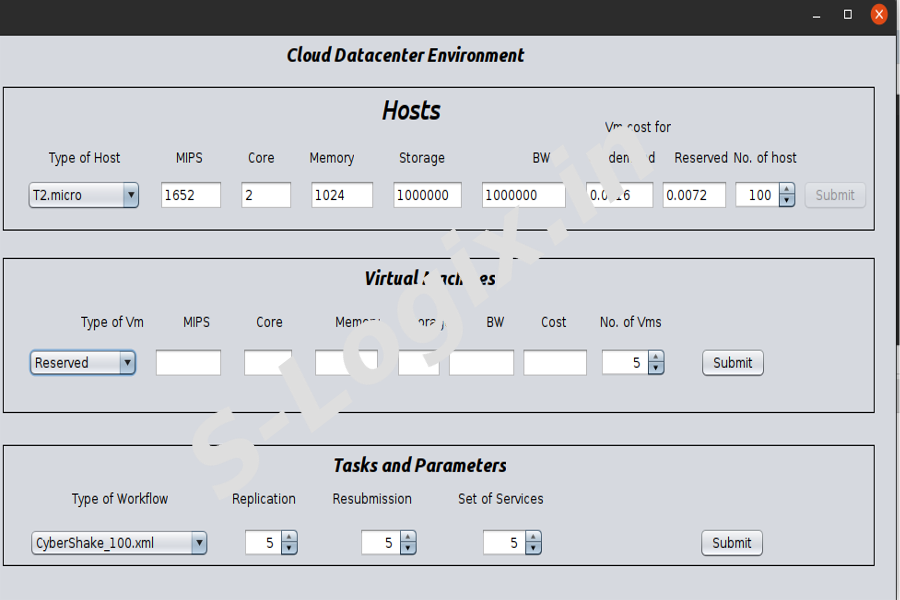
To set the values for hosts like type of host, mips, core, memory, storage, Bandwidth, vm cost and number of host.
Step 4
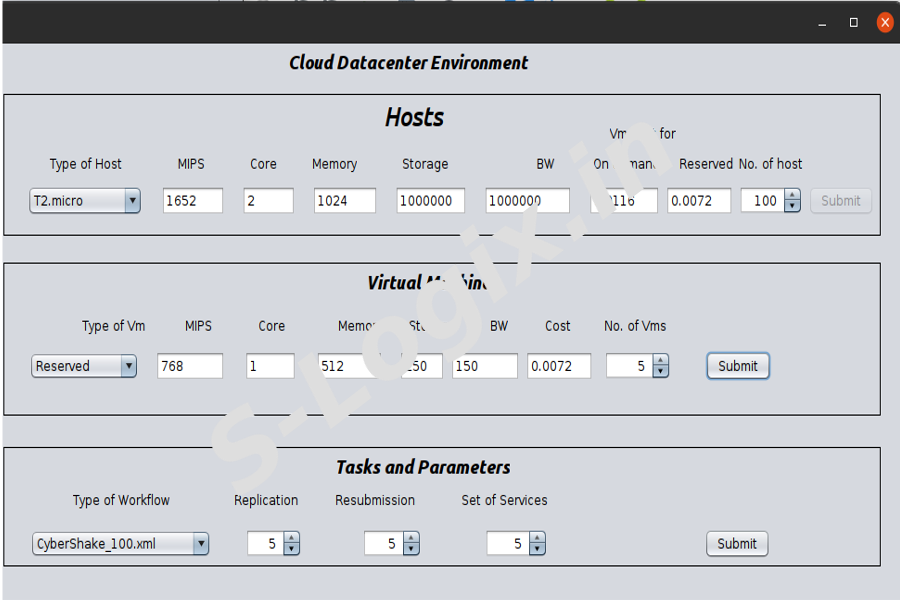
To set the values for virtual machine like types of vm, mips, core, memory, storage, bandwidth, cost and number of vms
Step 5
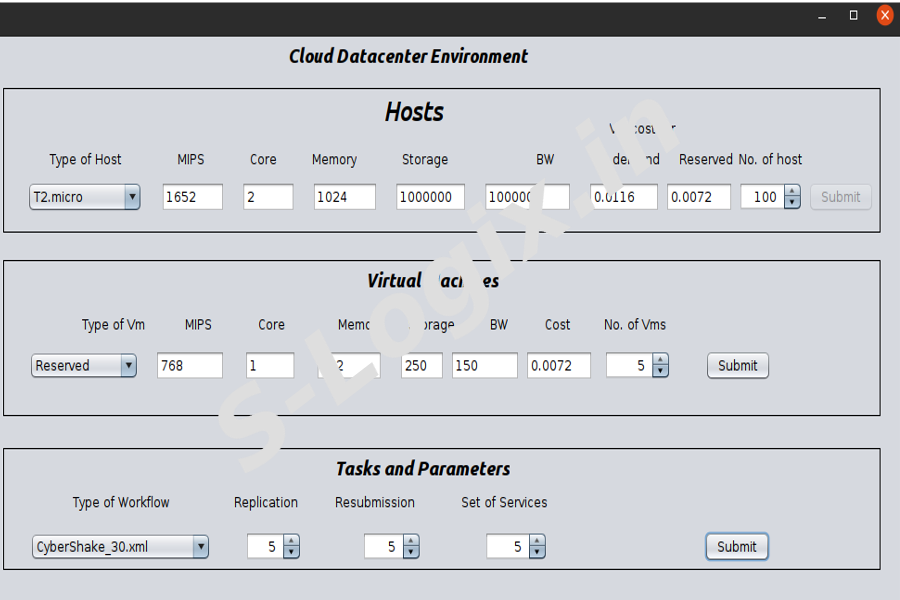
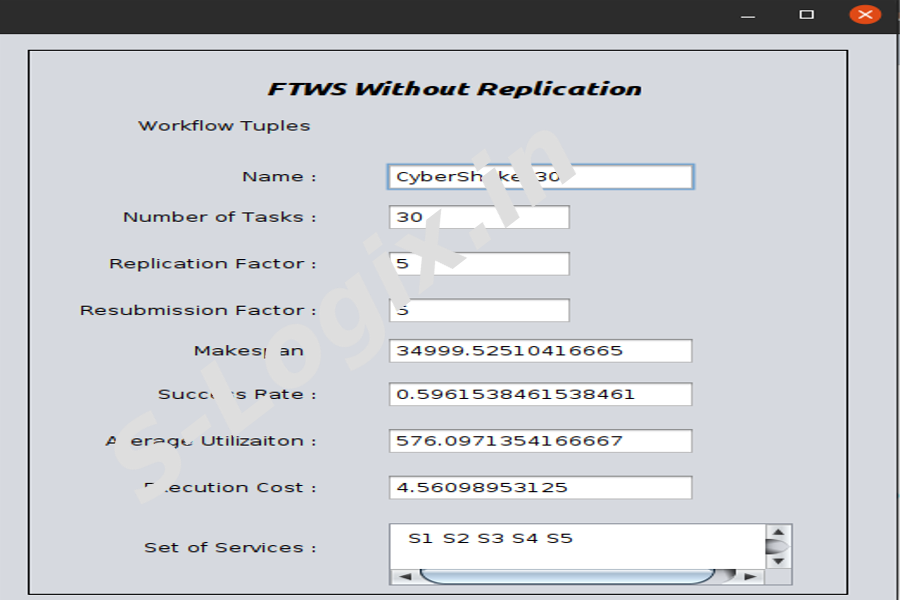
To add the type of workflow(CyberShake, Montage, Inspiral) and set the replication, resubmission and set of services.
Step 6
To activate Preprocessor step.
Step 7
To process the Fault tolerant without replication simulation.
Step 8
To get the result of workflow tuples according to the workflow file(CyberShake, Montage, Inspiral).
Step 9
Run the simulation.
Step 10
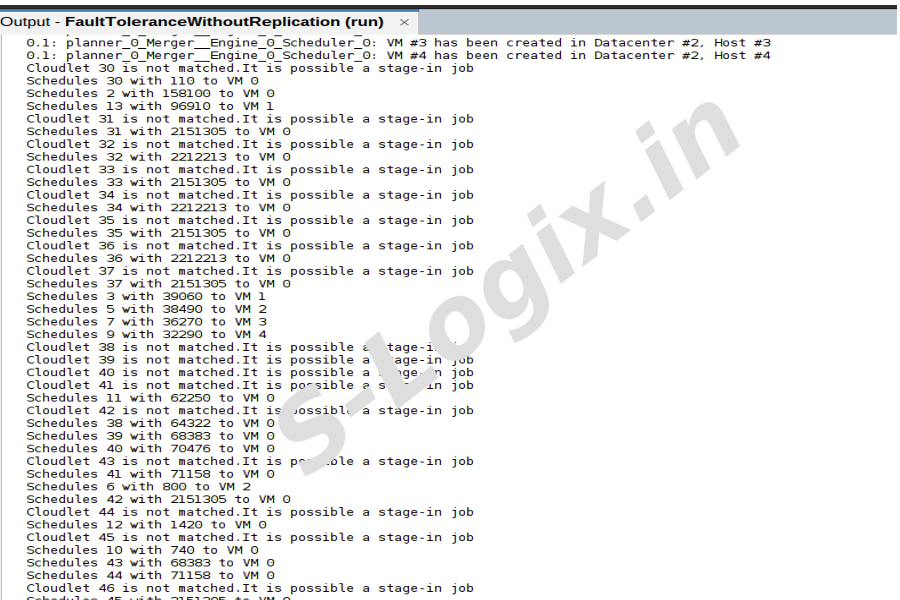
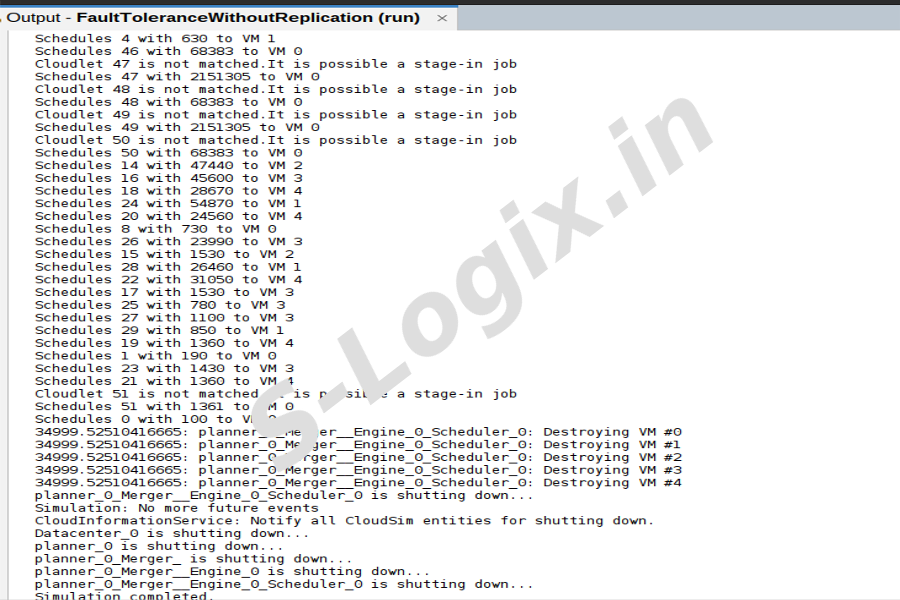
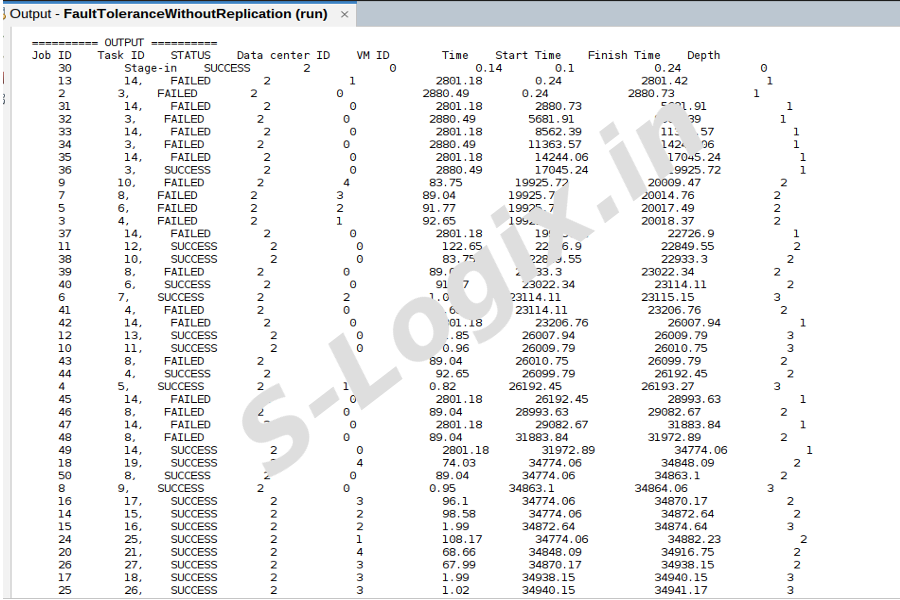
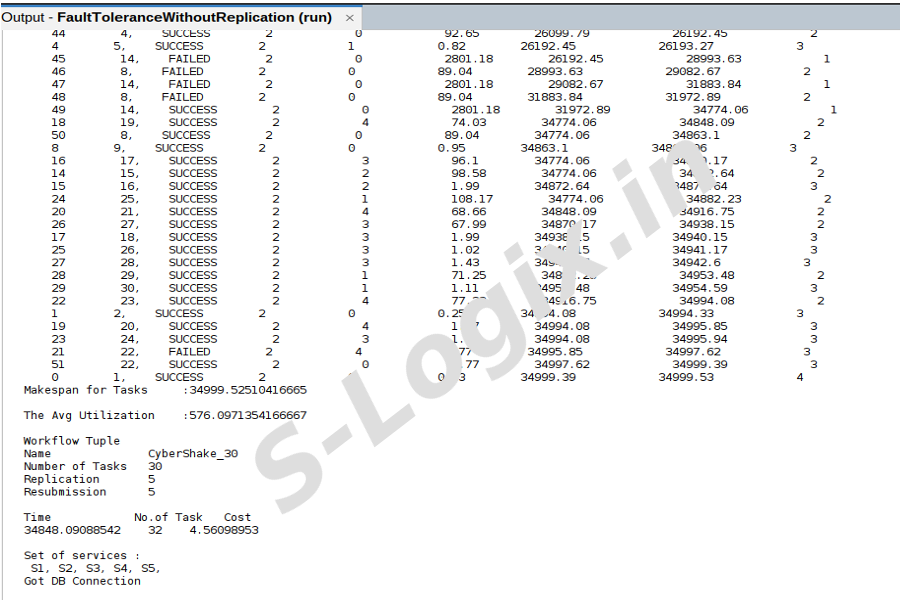
To get the cloudlet list.
Step 11
To get the results of Replication and Resubmission.
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix