How to Build and Evaluate an LSTM Model for Predicting Adult Income from a Dataset
Share
Condition for Building and Evaluating an LSTM Model for Predicting Adult Income from a Dataset
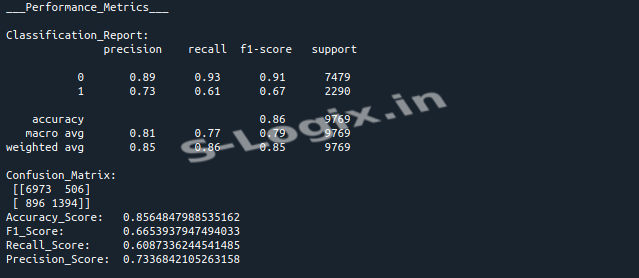
Description: The code preprocesses the Adult Income dataset by encoding categorical variables, normalizing features, and splitting the data into training and testing sets. It builds a Long Short-Term Memory (LSTM) model for binary classification to predict income categories (<=50k or >50k). The model's performance is evaluated using metrics such as accuracy, precision, recall, F1 score, and a confusion matrix.
Step-by-Step Process
Import Libraries: Import essential libraries like pandas, matplotlib, seaborn, and TensorFlow for data processing and model building.
Load and Inspect Data: Load the Adult Income dataset, check for missing or null values, and confirm the data types.
Preprocess Data: Encode categorical columns, compute a correlation matrix, and check the distribution of the target variable.
Scale Data: Normalize the feature data to ensure better convergence during model training.
Build and Train LSTM Model: Create an LSTM model with two LSTM layers and one dense output layer for binary classification. Train the model with training data.
Evaluate and Visualize: Evaluate the model's performance using accuracy, precision, recall, F1 score, and plot a confusion matrix.
Sample Source Code
# Import Necessary Libraries
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense, Input, LSTM
from tensorflow.keras.models import Model
from sklearn.metrics import (classification_report, confusion_matrix, accuracy_score,
f1_score, recall_score, precision_score)
# Output layer
output_layer = Dense(1, activation='sigmoid')(lstm_layer2)
# Build the model
lstm_model = Model(inputs=inputs, outputs=output_layer)
# Compile the model with Adam optimizer and binary crossentropy loss function
lstm_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return lstm_model
# Reshape input data to 3D (samples, timesteps, features)
X_train_lstm = X_train.reshape((X_train.shape[0], 1, X_train.shape[1]))
X_test_lstm = X_test.reshape((X_test.shape[0], 1, X_test.shape[1]))
# Instantiate and train the LSTM model
model = LSTM_model(X_train_lstm.shape)
model.summary()
 Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix