Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
To use character classes and POSIX character classes in regular expression using R
Set of characters enclose din a square bracket [ ].
Matches only the character enclose din the bracket Can be sued in conjunction with the quantifiers.
A caret (^) ahead of the expression negates the expression
| [aeiou] | Matches lower case vowels |
| [AEIOU] | Matches upper case vowels |
| [0123456789] | Matches any digits |
| [0-9] | Matches any digits |
| [a-z] | Matches any lower case letter |
| [A-Z] | Matches any upper case letters |
| [a-zA-Z0-9] | Matches any of above classes |
| [^aeiou] | Matches everything except aeiou |
| [^0-9] | Matches everything except digits |
Enclosed within double brackets [[ ]]
Works same like character classes
A caret (^) ahead of the expression negates the expression
| [[:lower:]] | Matches lower case letter |
| [[:upper:]] | Matches upper case letter |
| [[:alpha:]] | Matches letter |
| [[:digit:]] | Matches digits |
| [[:space:]] | Matches space characters(\t,\n,space etc) |
| [[:blank:]] | Matches blank characters |
| [[:alnum:]] | Matches Alphanumeric characters |
| [[:cntrl:]] | Matches control characters |
| [[:punct:]] | Matches punctuation characters |
| [[:xdigit:]] | Matches hexadecimal digits |
| [[:print:]] | Matches printable characters [[:alpha:]] [[:punct:]] and space |
| [[:graph:]] | Matches Graphical characters comprise [[:alpha:]] and [[:punct:]] |
library(readtext)
library(stringr)
data #To split the string using a pattern
data=unlist(str_split(data$text,” “))
#To matche character classes
#To match digit
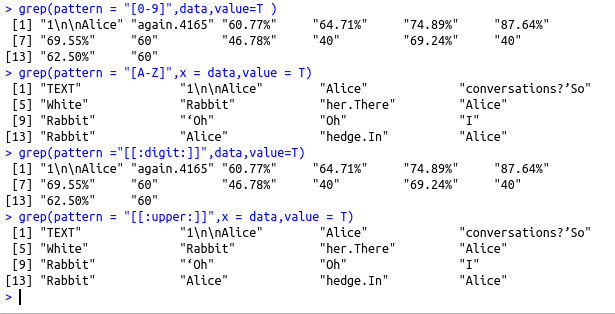
grep(pattern = “[0-9]”,data,value=T )
#To match any upper case letter
grep(pattern = “[A-Z]”,x = data,value = T)
#To match POSIX Character classes
#To match digit
grep(pattern =”[[:digit:]]”,data,value=T)
#To match any upper case letter
grep(pattern = “[[:upper:]]”,x = data,value = T)
#To match punctuation character
grep(pattern = “[[:punct:]]”,x = data,value = T)