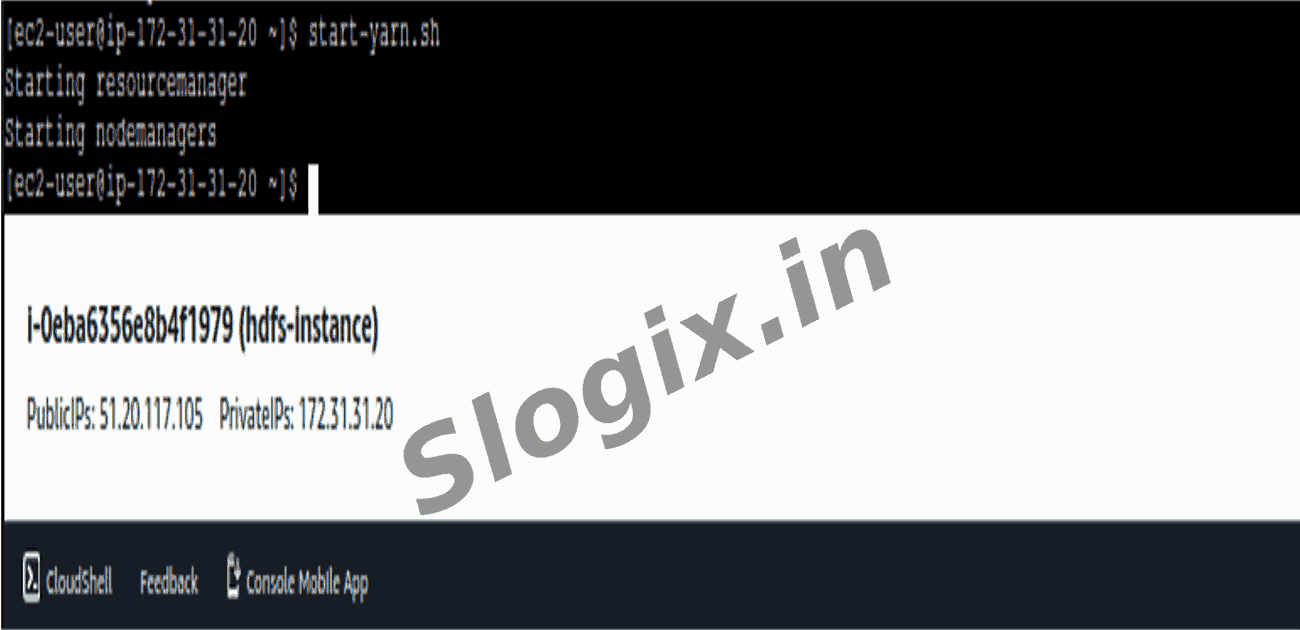
Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111





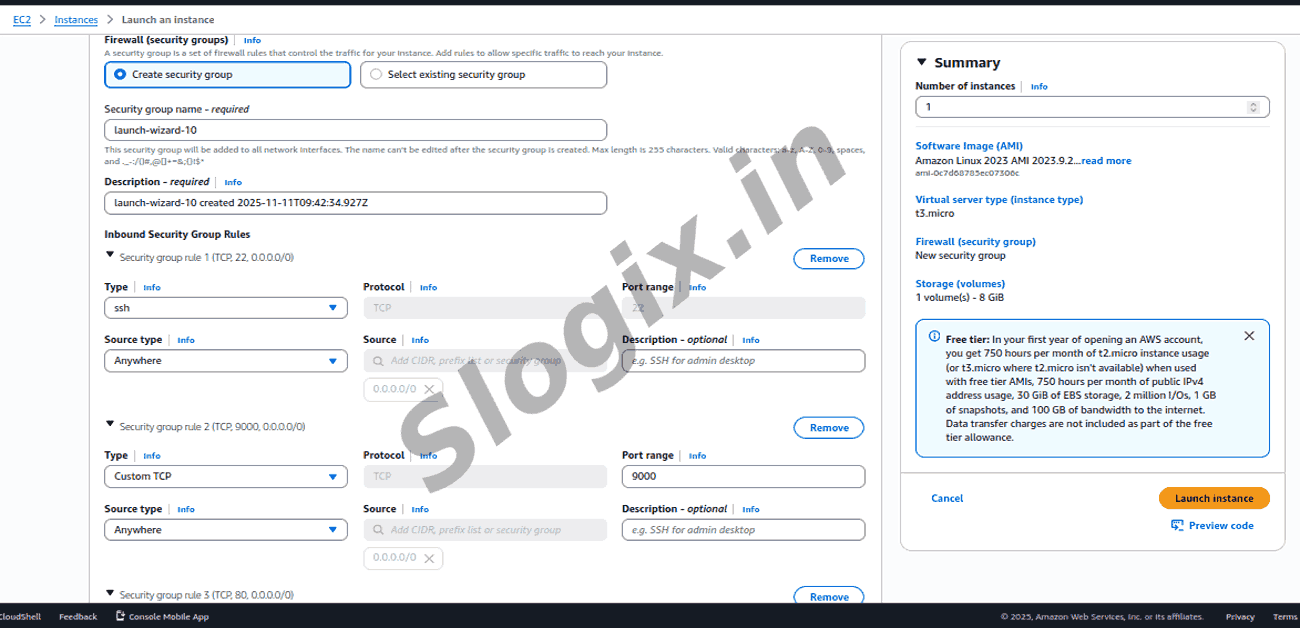
| Port | Purpose |
|---|---|
| 22 | SSH |
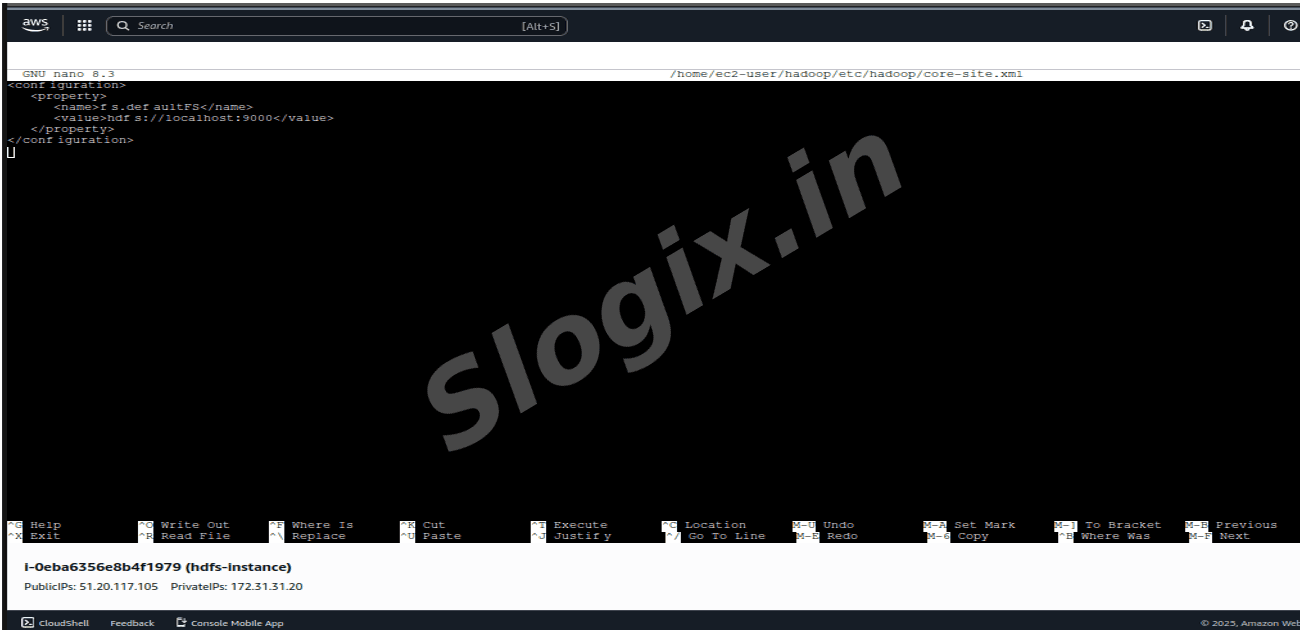
| 9000 | HDFS |
| 8088 | YARN UI (optional) |
| UI | Link |
|---|---|
| HDFS | http://<EC2_PUBLIC_IP>:9870 |
| YARN | http://<EC2_PUBLIC_IP>:8088 |