Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
Word frequency of the document can be done using Spark library. To count the word in the text file, spark loads the text file into a Resilient Distributed Dataset (RDD). Then it uses the flatMap function to split the lines into individual words. Once the words are extracted, it creates a map pair with word as key and value as 1. According to the map of key-value pair, the particular key values are aggregated using the reduceByKey function. Finally the output of word frequency is saved into HDFS.
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class SparkExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(“SparkWordCount”).setMaster(“local[3]”);
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> file = sc.textFile(“hdfs://localhost:54310/sparkinput/data.txt”);
JavaRDD<String> words = file.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(” “));
}
});
words = words.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String s) throws Exception {
if (s.trim().length() == 0) {
return false;
}
return true;
}
});
JavaPairRDD<String, Integer> wordToCountMap = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> wordCounts = wordToCountMap.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer first, Integer second) throws Exception {
return first + second;
}
});
wordCounts.saveAsTextFile(“hdfs://localhost:54310/sparkinput/output”)
}
}
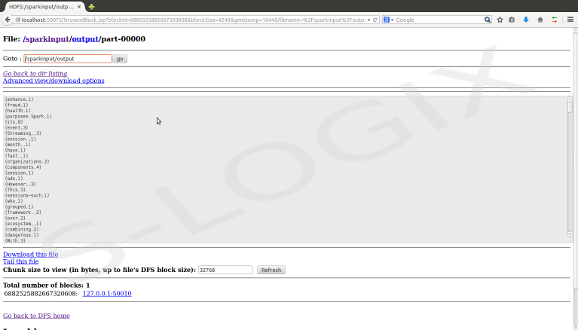
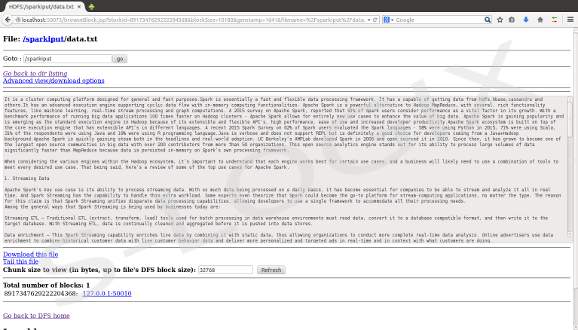
Spark input-HDFS
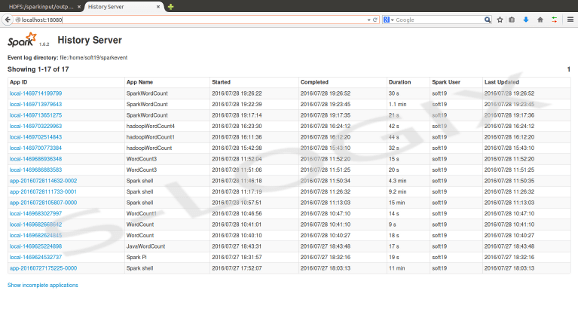
Spark job status
HDFS output