Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
The K-means clustering algorithm in Spark is implemented using Machine Learning Library (MLlib). It is an iterative algorithm that will make multiple passes over the data for efficiency, Hence any RDDs (Resilient Distributed dataset) given to it should be cached by the user. The spark.mllib implementation, initially trains a k-means model using set of parameters such as number of clusters, max number of iterations, and number of parallel runs. By executing the data points iteratively, the k-means algorithm returns the best cluster centers.
import java.util.regex.Pattern;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.mllib.clustering.KMeans;
import org.apache.spark.mllib.clustering.KMeansModel;
import org.apache.spark.mllib.linalg.Vector;
import org.apache.spark.mllib.linalg.Vectors;
public class JavaKMeans {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(“SparkKMeansExample”).setMaster(“local[3]”);
JavaSparkContext jsc = new JavaSparkContext(conf);
String path = “hdfs://localhost:54310/sparkinput/kmeans/kmeansdata.txt”;
JavaRDD<String> data = jsc.textFile(path);
JavaRDD<Vector> parsedData = data.map(new Function<String, Vector>() {
public Vector call(String s) {
String[] sarray = s.split(” “);
double[] values = new double[sarray.length];
for (int i = 0; i < sarray.length; i++) {
values[i] = Double.parseDouble(sarray[i]);
}
return Vectors.dense(values);}
});
parsedData.cache();
int numClusters = 4;
int numIterations = 20;
KMeansModel clusters = KMeans.train(parsedData.rdd(), numClusters, numIterations);
System.out.println(“Cluster centers:”);
for (Vector center : clusters.clusterCenters()) {
System.out.println(” ” + center);
}
}
}
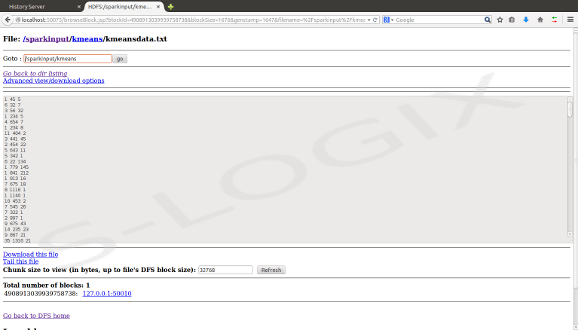
Spark input-HDFS
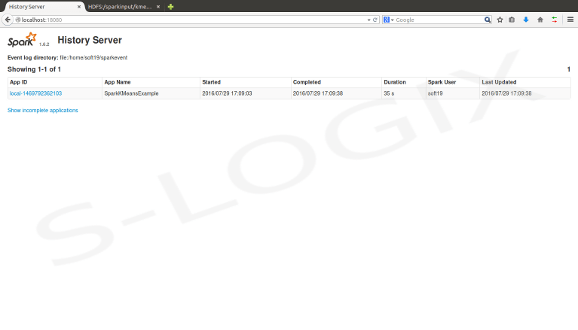
Job status Spark
Output
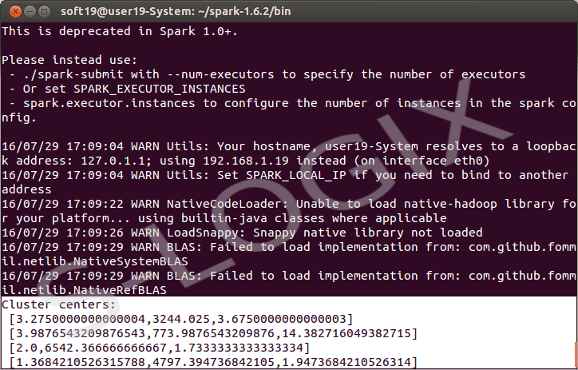
Cluster Centers