Research Breakthrough Possible @S-Logix
Research Breakthrough Possible @S-Logix
Office Address
- 2nd Floor, #7a, High School Road, Secretariat Colony Ambattur, Chennai-600053 (Landmark: SRM School) Tamil Nadu, India
- pro@slogix.in
- +91-81240 01111
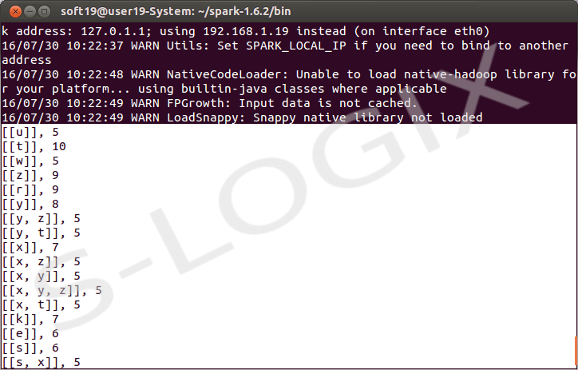
The frequent items are extracted from transactions using spark.mllib package. It provides a parallel implementation of FP-growth to mining frequent itemsets. The Spark takes JavaRDD of transactions as input, where each transaction is converted to set of items. Then FPGrowth algorithm is implemented with set of parameters setMinSupport and setNumPartitions. The setMinSupport and setNumPartitions define the minimum support required for an itemset to be identified as frequent and number of partitions used to distribute the work respectively. Finally, FPGrowth run function is executed which returns an FPGrowthModel that stores the frequent itemsets with their frequencies.
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.mllib.fpm.AssociationRules;
import org.apache.spark.mllib.fpm.FPGrowth;
import org.apache.spark.mllib.fpm.FPGrowthModel;
public class SparkFPGrowth {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName(“Spark-FPGrowth”).setMaster(“local[2]”);
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> data =c.textFile(“hdfs://localhost:54310/sparkinput/FPGrowth/fpgrowth.txt”);
JavaRDD<List<String>> transactions = data.map(new Function<String, List<String>>() {
public List<String> call(String line) {
String[] parts = line.split(” “);
return Arrays.asList(parts);
}} );
FPGrowth fpg = new FPGrowth().setMinSupport(0.2).setNumPartitions(10);
FPGrowthModel<String> model = fpg.run(transactions);
for (FPGrowth.FreqItemset<String>i1: model.freqItemsets().toJavaRDD().collect()) {
System.out.println(“[” + i1.javaItems() + “], ” + i1.freq());
}
sc.stop();
}}
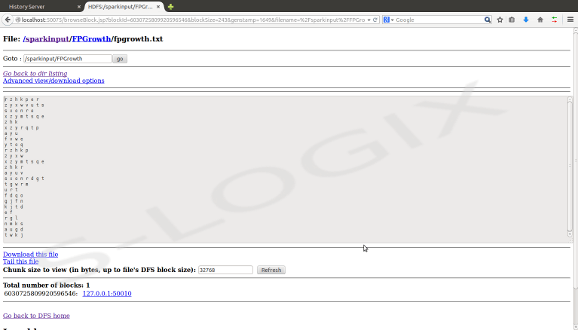
Spark input-HDFS
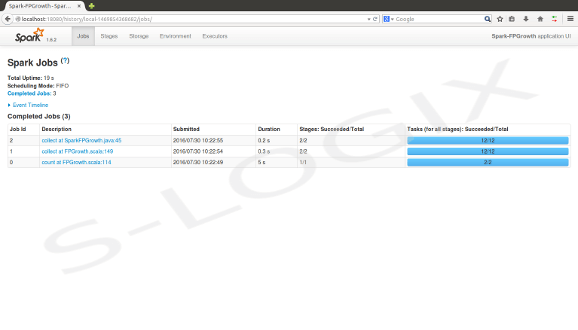
Spark job status
Frequent Itemset